|
|

Evaluating Hardware/ Software TradeoffsHardware extensions and the compilers that make them realBy Michael Tiemann (tiemann@cygnus.com), Gordon Irlam (gordoni@cygnus.com), Ian Lance-Taylor (ian@cygnus.com), Doug Evans (dje@cygnus.com), and Per Bothner (bothner@cygnus.com).IntroductionHigher performance with more bang for the buck is today's microprocessor game. We have the architectural expertise and technology to design radically new microprocessors, to craft new and sophisticated ISAs (Instruction Set Architectures). But we don't. Instead, the trend is to extend existing ISAs, giving performance boosts to current microprocessors. These extensions would be so much unused silicon if not for assembler and compiler support. It is the development software that ensures effective employment of new ISA features. It is the assemblers and compilers that make the hardware/software tradeoffs to make these extensions cost effective. Thus ISA extensions appear as software libraries or compiler enhancements for programmer and compiler use. Cygnus Solutions provides development tools and compilers for over 30 architectures and around 100 different microprocessors, a number of which incorporate ISA extensions. ISA extensions combine the better of two worlds: using existing microprocessor architecture, and adding new high-performance processor technology to boost performance. Today's microprocessors represent large investments in development software, existing application and operating software, and a programmer/talent pool. For example if you have a project and you choose a 68K or a SPARC, you have a wide range of operating, development and application software available for use. New architectures need time to build up an equivalent software base. Extensions let microprocessor architects incrementally add new technology as it comes on line. Some ISA extensions now emerging include:
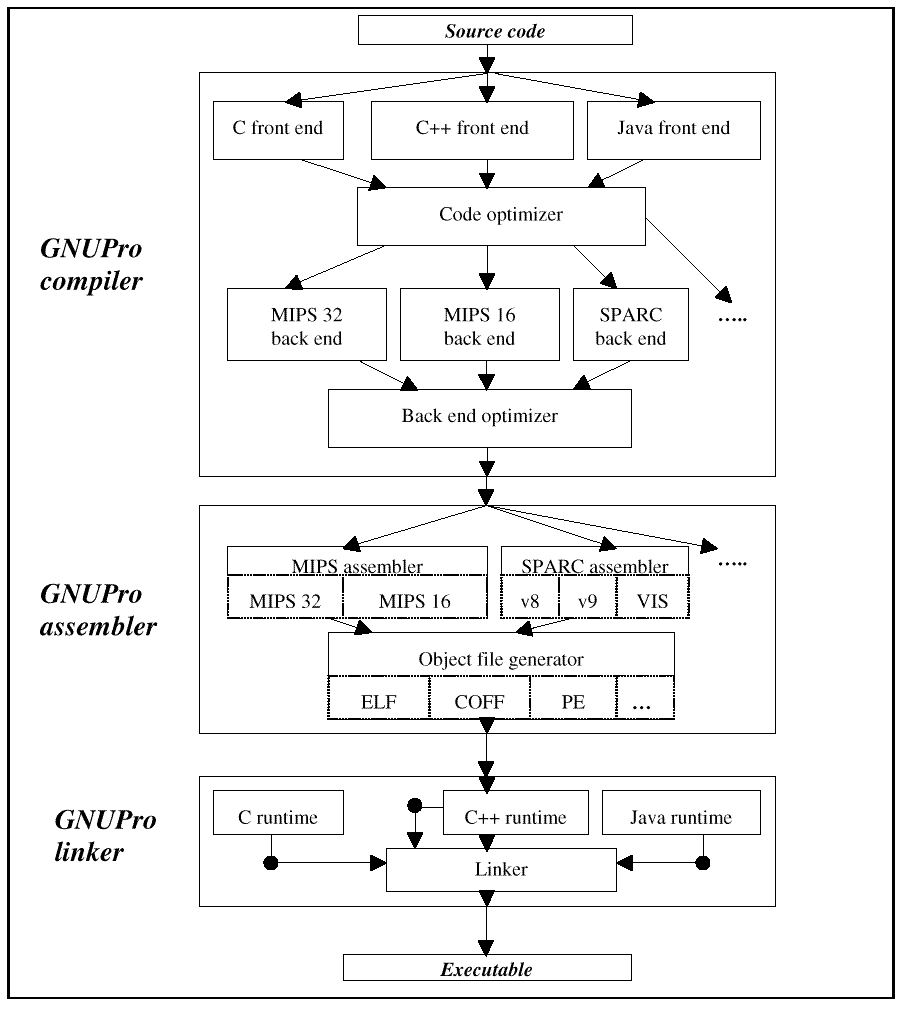
The GNU tools are highly modular and designed to support a wide range of architectures and processors. Figure 1 illustrates the GNU compiler/assembler/linker processing flow. It also shows where ISA extensions are added to the flow.
Figure1: ISA extensions and compiler/assembler/linker flow from source code to an executable Extension modelsISA extensions do more than just add a "mess" of instructions and leave their use to assembly writer and compiler folk. ISA extensions are in essence a computing model ¾ a set of new instructions and a structured, ordered way of using them. These new instructions are designed to work together, to support one another and to provide new capabilities to the existing ISA. For example, for DSP extensions, the new instructions were created to allow developers to set up and iterate through a DSP loop accumulating values for a series or for matrix or vector operating. The "model" in this case includes setting up addressing pointers, setting loop values and running an iterative DSP processing loop. The key to efficient DSP operation is to minimize "bookkeeping" operations and run very tight inner loop code. Thus extensions add a set of instructions to the hardware and ISA and a "computing model" to the ISA. The "computing model" provides the model of behavior that programmers can emulate to craft efficient code. The compiler is also structured to optimize that "computing model" or way of coding. This goes beyond the traditional compiler optimization, which is to optimize individual instructions or threads of instruction usage. Computing models make the point that ISA extensions are more than a few new instructions. Instead, they are a collection of operations that collectively support a model of processing. The closer library and application code follows those models, the more efficient code execution will be. For example, 16-/32-bit RISC enables a 32-bit machine to execute from 16-bit code and maximize code density. To do this, to shrink 32-bit instructions to 16-bit instructions, the number of instructions and number of registers referenced are reduced. Smaller instruction word fields equal less instructions and less register resources. Less register resources means that the compiler must be register stingy and users should minimize defined register use. Benefits of extending the Instruction SetThe benefits from using ISA extensions and deploying them in assembled and compiled code is not trivial. These extensions can deliver a great boost in performance or usability for specific application classes. Benefits include:
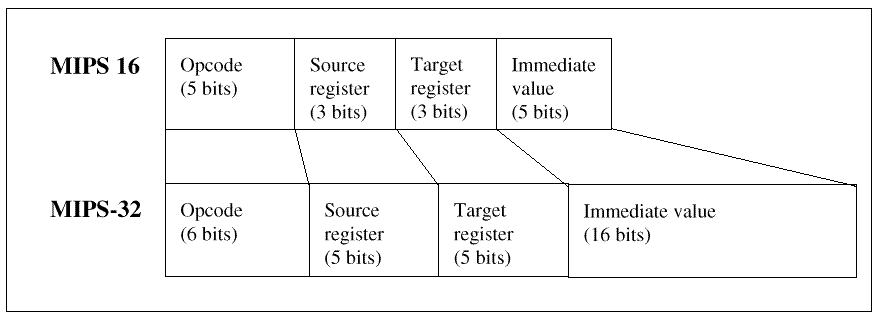
These ISA extensions allow developers to stay with standard microprocessor architectures, yet get critical performance boosts (or usability boosts) for their applications. MIPS-16, for example, enables programmers to use MIPS RISC for applications that need 32-bit processing power but are restricted in memory costs. See Figure 2 for an example of MIPS 16 instruction decompression.
Figure2: MIPS 16 decompression 16-/32-bit RISCEven today, the venerable 68K is used as a measure of code density. Many consider the 68K to set the standard for acceptable embedded system code density. The 68K design team made a number of very effective architectural decisions, decisions that have proved themselves over time. The key design parameters for the 68K was that it had a 32-bit data path (originally 32-bit registers with a 16-bit ALU and 16-bit memory interface) and 16-bit instructions. Most instructions fit into 16-bits with extensions for addressing and immediate data. This combination of 16-bit instructions and 32-bit data gave the 68K 32-bit processing power with roughly 16-bit ISA code density. On the other hand 32-bit RISCs were designed to create a very tight register-to-ALU cycle, a fast execution. To do this RISC designers minimized the instruction set -- the less instructions, the less logic depth, and thus faster execution. These techniques resulted in much simpler ISAs, some with fewer than 50 basic instructions; and in load-store architectures where most processing takes place between registers, and the only memory operations are load/store of registers. Crafting a 16-bit ISA from a 32-bit RISC ISA is not trivial. The smaller instruction word has smaller fields. Thus, it can only execute a smaller set of instructions using a smaller register set since the OP code field and register fields need to reduce to create 16 bit instructions. The first dynamic 16-/32-bit RISC was the brain child of the ARM design team. They came up with Thumb, which took a very clever approach to running a 16-bit ISA. The trick was to pick a 16-bit subset of the 32-bit ARM ISA, with less registers and instructions to reduce the field sizes. All instructions, 16- and 32-bit, enter the CPU the same, but when a special mode bit is set, the decoder decodes the 16-bit ISA, not the 32-bit ISA. The decoded instructions are then passed through an expansion block, that expands the decode to the 32-bit form, and the decoded 16-bit instructions are then passed on to the next stage in the pipeline. The 16-bit instructions are retrieved, decoded and then expanded to 32-bit instructions for execution. The MIPS-16 takes a similar approach. Figure 2 shows the decode expansion block that expands the 16-bit instructions to 32-bitters. The dynamic 16-/32-bit RISCs are different than some RISCs like the Hitachi SH series. Those have fixed 16-bit ISAs and a 32-bit datapath. The ARM Thumb and the MIPS-16 are 32-bit machines that can dynamically switch to run with a reduced 16-bit ISA. A mode or status bit sets 16 or 32-bit ISA mode. That bit cannot be set at any time during execution. It can only be set during a call or return, insuring that 16- or 32-bit ISA operation is defined at the function or subroutine level, or higher. The key to dynamic 16-/32-bitters is their compilers. They run compiled code and the compiler compiles 16- or 32-bit ISA code. A switch or flag is set, and that indicates whether to compile a function or file as 16- or 32-bit code. With the GNU MIPS-16 assembler/compiler, the switch is �-mips16'. The decision of what is 16- or 32-bit ISA code is made at compile time, not runtime. However, the generated code will set the proper ISA mode bit when switching from 32- to 16-bit code or vice versa. MIPS-16
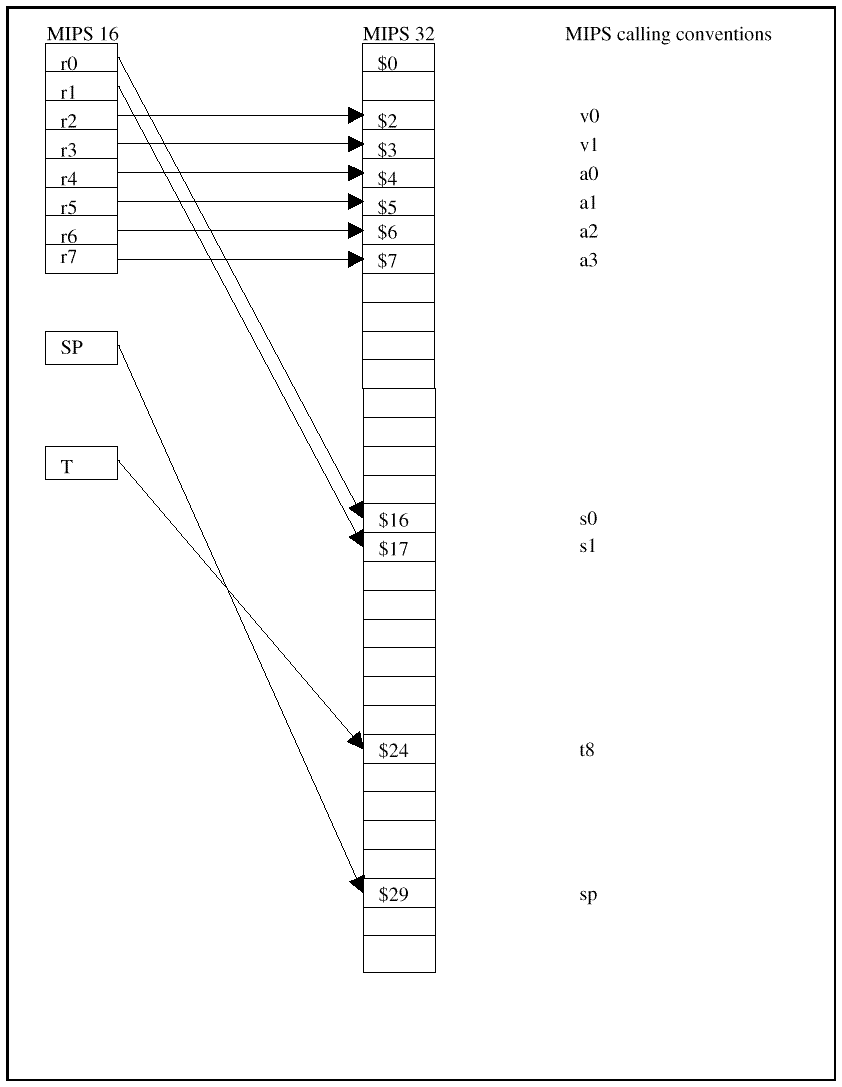
Figure 3: Mapping compressed MIPS-16 instructions The MIPS-16 ISA is the 16-bit ISA derived from the 32-bit MIPS I ISA. It supports the full range of MIPS ISAs. To fit into 16 bits, the MIPS-16 uses 5-bits for its major op code field and function field (they were 6-bits), 3-bits for the register fields (they were 5 bits). Additionally, the MIPS-16 uses only two register fields, rather than the three of the MIPS I ISA. And it shrinks the immediate value field from 16- to 5-bits. Figure 3 compares the MIPS-32 and MIPS-16 instruction fields. The 16-bit ISA's restricted register set directly effects compiler register allocation strategy. With the normal MIPS-32 ISA, when the compiler allocates registers for a complex expression, it normally feels free to allocate a new register any time one is needed. Usually there are enough registers, and if there are not enough, if too many registers are needed, some are merged or spilled to the stack. In the MIPS-16 ISA, which has fewer registers than the 32-bit ISA, the compiler is forced to use argument registers as temporary registers. Other changes include adding a special stack pointer instead of using a general register. The MIPS-16 only has 8 general registers, too few to use on as designated stack pointer. Figure 4 shows the MIPS-16 and MIPS-32 register usage.
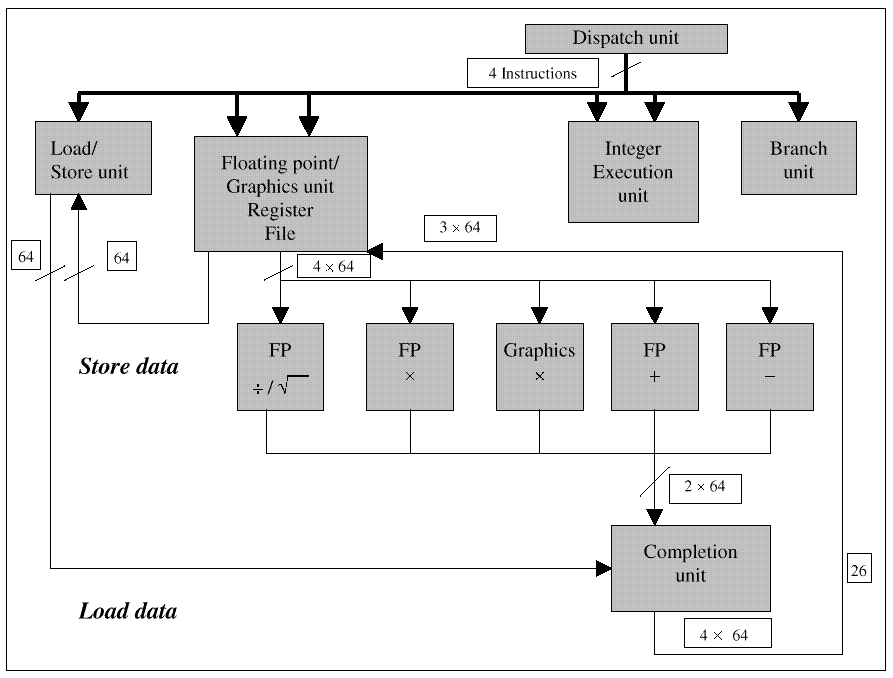
Figure 4: MIPS register mapping Switching between the MIPS-16 and 32-bit MIPS I ISAs is done through the jump and link instructions: JALX, JALR (Jump And Link eXchange). JALX jumps and saves the next address in a link register and is used for subroutine calls. The JALR returns to the address in the link register. Using JALX, a 32-bit ISA routine can call a 16-bit ISA routine and vice versa. JALR and JR (jump return) can also set or reset the ISA mode bit. The ISA mode bit can also be changed when an exception occurs. Generally exceptions are handled by the system in full 32-bit ISA mode. There were some interesting consequences of implementing a 16-bit MIPS ISA. For example, the MIPS-16 ISA dos not permit access to the floating-point registers. This becomes a problem since the MIPS calling convention is meant to pass floating-point values in the floating-point registers. This could be a real problem when a 32-bit MIPS-32 function calls a 16-bit MIPS-16 function and passes a floating-point argument. The MIPS-16 code cannot access that value. We fixed the problem by making sure that the compiler emits a 32-bit stub for any 16-bit function that took a floating-point argument. The stub copies the floating-point register into regular argument registers, and that then jump to the 16-bit function. The linker arranges for all calls from 32-bit functions to go to the 32-bit stub. If the 32-bit stub is never called, the linker deletes it. When a 16-bit function calls a function with a floating-point argument, the compiler adds a 32-bit stub. The linker arranges the function call to go through the stub if calling a 32-bit function; it will go directly to a 16-bit function. Visual/Math ISAsSomeone once noted that many applications manage to turn 32-bit microprocessors into 8-bit processors. Unfortunately, that's true for many standard programming tasks. Examples include: looking for the EOF character in a text block; or searching for a specific character in a string. These operations involve a 32-bit processor searching for an 8-bit or character value, one byte at a time. Yes, you can speed it up by doing AND compares and testing on matches, but it still takes processing time. Another processing sink for inefficient cycles is 8-bit or 16-bit pixel processing on a 32-bit or 64-bit data path. Rarely can such processing use the full datapath bandwidth of the CPU. Instead it throttles down, processing to the graphic field size, and wastes datapath resources. The idea behind the visual/graphics ISA extensions is to perform multiple field operations across the datapath width. Thus, for a 64-bit system, one instruction can do eight 8-bit adds, compares, or logical ANDs, for example. That is an 8X speed up. Sun Microsystems was the first of the major RISC design houses or chip vendors to implement a "Visual Instruction Set" (VIS) with v9 of its SPARC architecture specification. V9, and VIS, first appeared in UltraSPARC, Sun's 4th generation superscalar, high performance RISC. Rumor has it that Sun developed VIS as a counter to Silicon Graphics and that, internally, the project went under a code name of "SGI" which stands for "Sun Graphics Instructions" in reality. Cygnus Solutions was the first to produce a commercial compiler for V9 processors. Others have followed. MIPS, for example, has the MDMX extensions, and Intel (along with competitors) has introduced its MMX extensions. Sun's Visual Instruction SetSun's UltraSPARC is a superscalar, 4th generation RISC. It can issue up to four instructions per pipeline cycle. It is also Sun's first 64-bit machine � the main datapaths are 64-bits wide, ideal for graphics or multimedia data processing. It has four execution units: the Branch, Integer Execution, the Load/Store and Floating-point/Graphics Units. With UltraSPARC Sun, architects add special graphics/math processing capabilities in the FPU, now known as the Floating-Point/Graphics Execution Unit. The FPU/GEU can execute up to two floating-point/graphics operations (FGops) and one Floating-Point load/store operation in each pipeline clock cycle. These operations, except for divide and square root, are fully pipelined. They can complete out-of-order without stalling the execution of FGops. Figure 5 shows the UltraSPARC execution units, including the FPU/GEU and its five sub-units. The FPU/GEC Unit works with its own set of 32 double-precision floating-point registers. It also has 4 sets of FP condition code registers for more parallelism.
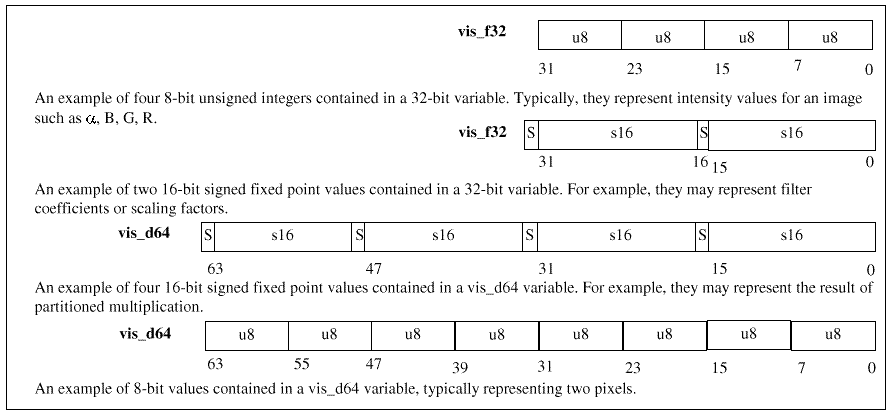
Figure 5: UltraSPARC execution units In processing image data, the code uses the UltraSPARC 32 integer registers for addressing the data, and the 32 FPU registers for manipulating images. Pixel information is typically stored as four 8-bit or 16-bit integer values. Typically these four values represent red, green, blue (RGB) and the alpha (a ) information for the pixel. Figure 6 shows the UltraSPARC V9 packed data formats.
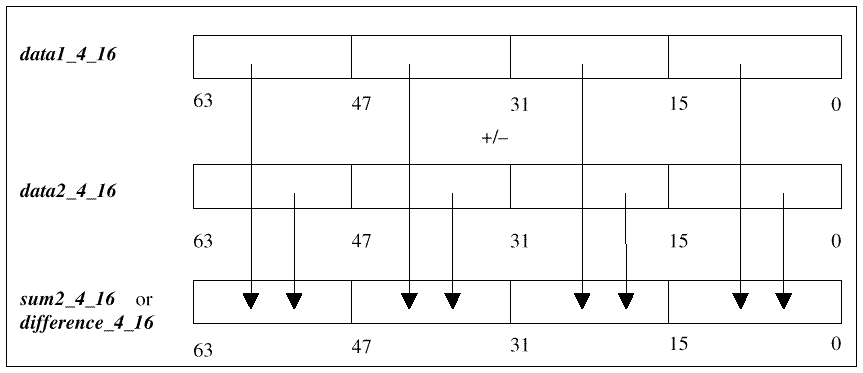
Figure 6: Partitioned data formats The UltraSPARC Visual Instruction Set instructions include: pixel expand/pack, partitioned add/MPY/Compare, align, edge handling, array addressing, merge, pixel distance and logical operations. Figure 7 shows the addition of two 64-bit partitioned words with four 16-bit components.
Figure 7: UltraSPARC partitioned multiply The GNU assembler has a very modular structure. Adding the new Sun UltraSPARC VIS instructions involved little more than adding a few operands to the opcode table. The VIS graphics instructions are not represented in the compiler. Most programmers use these operations in assembler, typically in libraries and special utilities. However, GCC's in-line capability enables developers to deploy the VIS multi-field processing features in key inner loop routines and functions. The assembler enables developers to write assembly code that uses instructions such as the following example's input. fpadd16 %f2,%f4,%f6 This instruction adds four 16-bit floating bit values in each of f2 and f4 and store the result into f6. Inside a C function, we can use GCC's inline assembly feature with the following input. typedef double pixel4x16; This function will add together two sets of four 16-bit pixel values. If we have a frame buffer, we can then take advantage of GCC's ability to inline functions to write the following input. vector_fpadd16 (pixel4x16 *vec1, pixel4x16
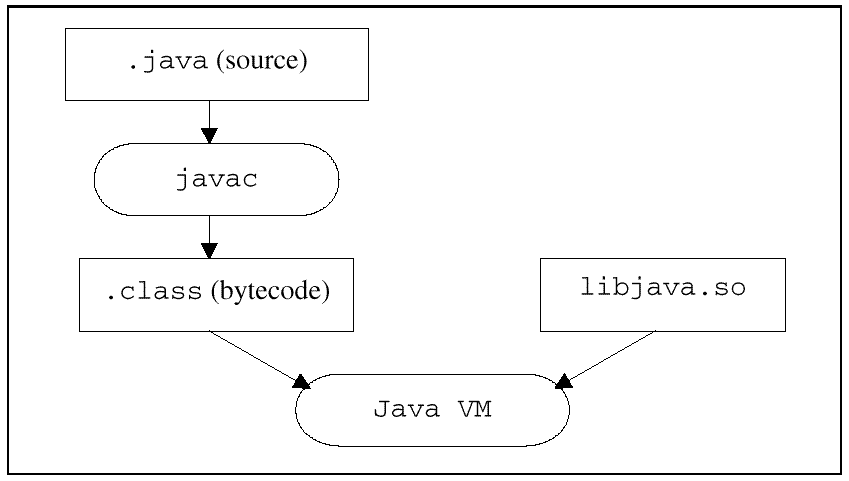
*vec2, pixel4x16 *res, int len) This routine will add together two vectors, or equivalently, two regions of memory, comprised of pixel values. The code generated by the compiler for this routine looks like the following output. vector_fpadd16: As the resulting machine code shows, a well-designed compiler is able to provide end users with high performance access to instruction set extensions, such as the VIS instruction set. Equally important, the end user is able to access such features entirely from within a C or C++ program. JAVAJava has become a major factor in computing. Java is interesting in that it's a software, not hardware, extension. Java defines a Java "Virtual Machine" as a software CPU that executes Java instructions. This machine is platform independent and can run on many different CPUs. Java defines its own software ISA. Java's advantages were not in speed. It is defined as a byte-coded interpretive language. Java instructions are individually decoded and interpreted, which can make for slower executions on the order of 20 to 40 times slower than C or C++ code. Java does have its advantages though. For one thing, it's a newer language, one designed for multimedia and GUI operations. For another, it's a subset/superset of C/C++. Among other things, Java does not support pointers. Pointers were the glory of C, enabling programmers great flexibility. They were also its bane; problems with pointers trouble many developers. Java takes a much more disciplined approach to pointers: they are called "references" and are either null or point to an actual object; no dangling pointers, no de-referencing pointers (to cause an exception). Java also fixes a number C/C++ problems: array indexing is checked (out-of-bounds index equaling an exception) and fields have defined initial values. In many ways, Java is a smaller, simpler and better C and C++. Unlike C and C++, it defines a runtime or "Virtual Machine" that contains many of the functions routinely compiled into C programs. With Java, they are part of the virtual machine. Additionally, Java forgoes traditional memory management: it supports automatic memory management and garbage collection. The traditional Java implementation model is to compile Java source into .class files containing machine-independent bye-code instructions. These .class files are downloaded and interpreted by a browser or a Java "Virtual Machine." Figure 8 shows the typical JAVA implementation.
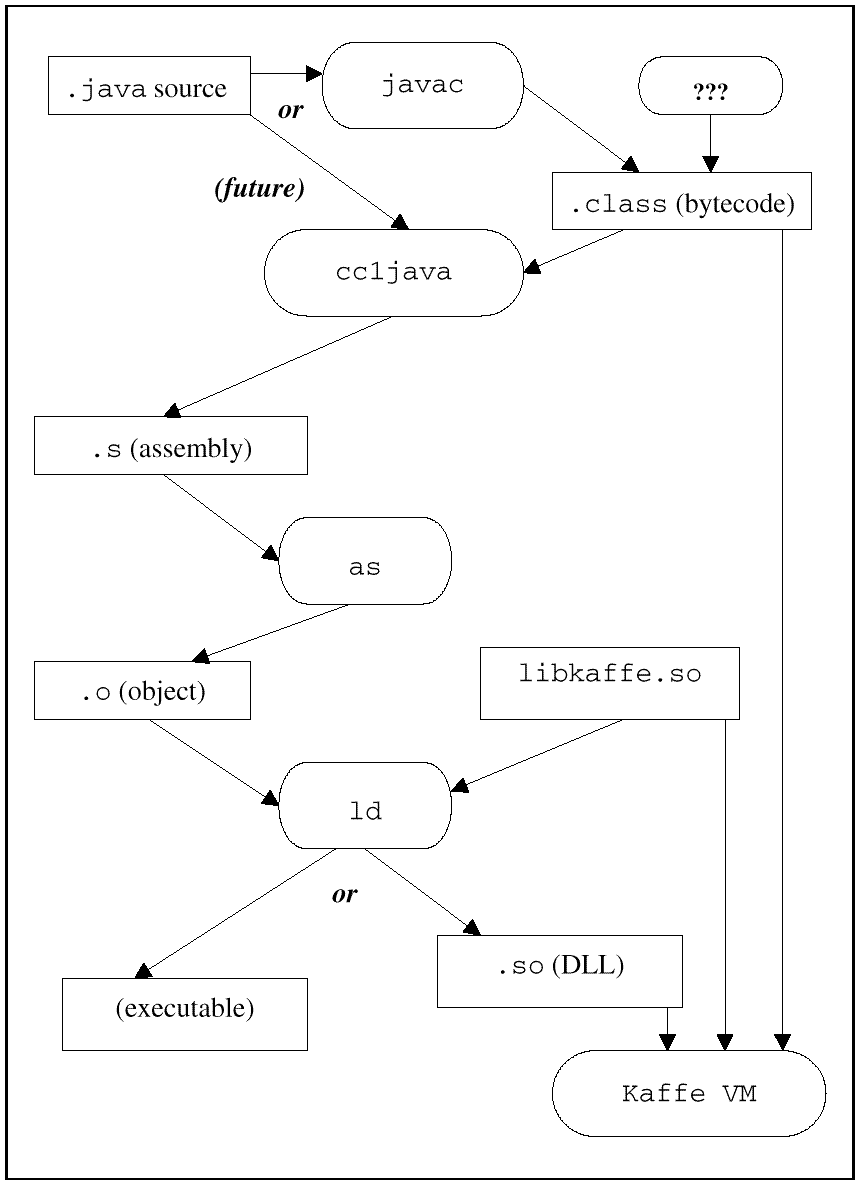
Figure 8: Typical Java implementation Interpreting Java byte-codes makes Java code many times slower than comparable C or C++ programs. One approach to improving this situation is "Just-In-Time" (JIT) compilers. These dynamically translate byte-codes into machine code just before a method is first executed. This is a major advance over slower interpretation, but has the drawback that the JIT compilation must be done each time the application executes. Moreover, since the JIT compiler must make use of run-time resources to compile, it cannot devote much time to serious optimizations. Compilers can because they use host development resources, not runtime resources. Additionally, JIT compilers need memory resources to run; this can be very wasteful for embedded systems that try to minimize memory costs. No JIT compiler today fits in less than 512 KB of local memory. That's wasteful for many memory critical embedded applications. Compiled JavaCompiling Java eliminates many common Java problems, especially for speed of execution. Compiled Java will be platform specific; however, many programmers are more interested in Java as a modern language, extending clean C/C++ program output. Although Java is, still, without platform independent execution, especially with its large interpreter performance penalty, a compiled Java still defines a Java virtual machine. However, code developed for that machine is compiled on the host, converting Java source code to platform-specific runtime code. The Java runtime, which provides features such as garbage collection, and exception handling, is still needed. However, for many embedded applications, it is possible to dispense with the need for a full blown Java VM or JIT compiler. Cygnus Solutions is working on a Java programming environment that uses a conventional compiler, linker and debugger. These are enhanced versions of the existing GNUPro C/C++ development tools that have been ported to most development systems for just about every microprocessor and micro-controller in use. With the GNUPro Java compiler, Java byte-codes (or source) will be portable to a wide range of development platforms and targets. Such an approach to implementing Java is also expected to deliver very high performance. See Figure 9 for an example of compiled Java. The core of Cygnus Solutions' compiled Java is the jcl compiler, a new GCC front-end. This is similar to other GNU front-ends such as cc1plus for C++, and shares most of the front-end code. This new compiler, jcl, is unique in that it can read-in and compile either Java source files or Java byte-codes. Future versions will use an integrated parser that handles both source code and byte-codes. Even with source code operation, it's important to be able to handle byte-codes to support Java code from other tools and to use Java byte-code libraries. The basic strategy for translating Java stack-oriented byte-code operations is to convert Java's stack-oriented operations into operations on variables. jcl creates a dummy local variable for each Java stack slot or local variable. These are mapped into GCC "virtual registers" and, then, into standard GCC register allocation assigns each "virtual register" to a hard register or to a C/C++ stack location. The jcl program creates standard assembler files that are processed by the standard unmodified GNU assembler. The resulting object files can go into a dynamic or static library, or they can be linked together with the runtime into an executable. The standard linker needs to be able to support static initializers, but it already does that for C++. A compiled Java program still needs a Java run-time environment, just as C++ or Ada requires its own run-time. Java, however, requires more run-time support than these mainstream languages. It needs support for threads, garbage collection, type reflection and all the primitive Java methods, as well as being able to dynamically load new Java byte-coded classes. This last feature may not be a requirement in some embedded applications that use fixed code. Cygnus Solutions is integrating Kaffe, a version of the Java run-time or Java Virtual Machine, with its Java compiler. Kaffe was developed by Tim Wilkinson who made it publicly available on the Internet. A major factor in Java's success in becoming a mainstream programming language is having mainstream implementation techniques (specifically, an optimizing, ahead-of-time compiler that allows much better optimization along with much faster application start-up times than with JIT translators). Cygnus Solutions is writing a Java front-end for the GNU compiler, GCC, in order to translate Java bytecodes to machine code. This will take advantage of a widely used, proven technology in order to solve many future needs. See Figure 9 to see how Java works.
Figure 9: Compiled Java |