Cygnus Implementation
of the
JavaTM Language
Architecture and Design Manual
June 30, 1998
Cygnus Solutions
Trademarks: Cygnus, Cygnus Solutions, Cygnus Foundry, and GNUPro are trademarks or registered trademarks of Cygnus Solutions. Java and all Java-based trademarks and logos are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries.
Copyright: Copyright 1998 Cygnus Solutions. Unauthorized reproduction prohibited.
Contents
-
1.0 Introduction
-
1.1 The Java Language
1.2 Embedded Systems
1.3 Embedded Systems and Java
1.4 Cygnus' Embedded Java Solution
2.0 The Java Language
-
2.1 Java Interpretation
2.2 Java Compilation
2.3 Combined Systems
2.4 Source Language Character Set Issues
3.0 The Java Runtime
-
3.1 Memory Size
3.2 Low-level Interfaces
3.3 Threading
3.4 Garbage Collection
4.0 The Java Class Libraries
-
4.1 Java Class Library Overview
4.2 Class Library Selection
4.3 Class and Method Selection
4.4 Library Implementation
5.0 User Interface Design
-
5.1 GNUPro Java Enhancements
5.2 Cygnus Foundry Java Enhancements
6.0 Debugging
-
6.1 The GNUPro Debugger
6.2 The JVMDI
6.3 User Interface Issues
6.4 Debugging Compiled Java
6.5 Debugging Interpreted Java
7.0 Compatibility Issues
-
7.1 The Java Native Interface
7.2 C/C++ and Interpreted Java
7.3 C/C++ and Compiled Java
7.4 Interpreted Java and Compiled Java
7.5 Dual Java System Support
Bibliography
1.0 Introduction
As Java evolves, it's clear the language has potential for use in embedded systems. A major factor in Java's success to this point is the use of portable bytecodes. However, Java cannot become a mainstream programming language without mainstream implementation techniques, specifically, an optimizing ahead-of-time compiler that allows much better optimization and faster application startup times than with just-in-time (JIT) translators. Cygnus Foundry Java Edition is a Java front-end for the GNUPro compiler (GCC) that translates Java bytecodes to machine code. Cygnus Foundry Java Edition produces code with the size and performance of C/C++. This document discusses the architecture and design of Cygnus Foundry Java Edition.1.1 The Java Language
The Java programming language was developed at Sun Microsystems as a language for programming an experimental PDA known as the Star7. While the experimental device was not manufactured, Java found life on the World Wide Web.Java is an object oriented programming language. It contains proven features from a number of successful programming languages, and since it is a cleanly designed language, many find it easier to master than C++. The language also has more safety features than C or C++. For example:
- arrays are bounds checked
- type rules are strictly enforced
- programs are "verified" for execution safety and to protect the execution environment from rogue programs or damage from programming errors
The ubiquitous feature of the language is that it is generally an interpreted language. An interpretable representation of the program, known as the bytecode form, can be interpreted by an appropriate interpreter on any machine. On the Web, such programs contained in applets can be executed within any browser that supports Java.
With its use of bytecodes, Java programs are generally more portable than C or C++ programs. Language standards for C and C++ leave many fundamental language properties to be defined by the implementation. The Java language defines many of these properties in order to guarantee the portable properties of the bytecode representation of Java programs.
In Java, when an object is no longer used, the storage is reclaimed by the runtime system automatically. In addition, the language also supports the writing of threaded programs. A thread is an independent "thread of control" that can run independently of the rest of the program.
An often cited problem in C and C++ are bugs related to the management of storage. Dangling pointers and memory leaks are very real problems in programs of any complexity.
Manual memory management in the presence of threads or complex data structures is difficult and error prone. Java uses a technique known as garbage collection (GC) to track and reclaim storage for objects that have ceased to be referenced. The Java runtime environment contains a garbage collector that runs, typically on a separate thread, while the application is running. The collector occasionally gains control, gathers up the objects that are currently dead, and puts the storage back on the free list.
Garbage collection is automatic and requires no programmer intervention. This is an old technique that has been well studied. There are many algorithms and strategies to pick from. The criterion for selection may depend on many factors:
- compiler support
- multi-thread requirements
- real-time requirements
- availability and speed of manipulating page protection
- application usage patterns
- tightness of memory
No one method is "best." The ideal solution involves developing a framework in which different algorithms can be evaluated. Because GC ties in with object management, it may be desirable to tune and re-compile the Java system for best performance.
The availability of thread primitives makes much easier the development of programs that take advantage of parallelism. They are helpful in developing user interface code, and depending on the underlying system, can make use of multiple processors.
The non-portability of threads in other languages has historically made it more difficult to write portable programs that use threads. Including threads in the language means they will be implemented consistently with respect to other language features such as garbage collection.
1.2 Embedded Systems
An embedded system is a specialized computer system that is part of a larger system or machine. Typically, an embedded system is housed on a single microprocessor board with the programs stored in ROM. Virtually all appliances that have a digital interface --- watches, microwaves, VCRs, cars --- utilize embedded systems. Some embedded systems include an operating system, but many are so specialized that the entire logic can be implemented as a single program.Although software development for general purpose computers and for embedded systems has much in common, software development for embedded systems is driven by substantially different needs and considerations. In particular, software for embedded systems is typically required to be as compact as possible. Small code size reduces device cost and may contribute also to speed of execution.
A significant impediment to embedded systems development has been the vast variety of embedded system platforms. Unlike the general purpose computer arena in which a few processors command most of the market, in the embedded systems arena, hundreds of different processors compete for market share. Porting embedded systems software from one processor to another has therefore been required in order to achieve software reuse. Such porting can only be performed by skilled programmers and is laborious, time-consuming, and error-prone.
1.3 Embedded Systems and Java
Sun's motto for Java is "Write once, run anywhere." As part of that, Sun has been pushing Java as also suitable for embedded systems, announcing specifications for "EmbeddedJava" and "Personal Java" specifications. The latter is primarily a restricted library that a Java application can expect to be able to use."Embedded systems" covers a large spectrum of devices, ranging from 4-bit chips with tens of bytes of RAM, to 32- and 64-bit systems with megabytes (MB) of RAM. It may be difficult to squeeze a reasonably complete implementation of Java into less than one MB. However, some have managed to squeeze a much-reduced Java into credit-card-sized "smart cards" with about 100kB. In general, there is less memory available than in the typical desktop environment where Java usually runs.
Java has been in workstation environments for a few years. For most embedded situations, a custom Java environment must be built. This environment includes a port of a Java virtual machine (VM), plus all of the cross development tools. Many such tools are relatively new in number, and suffer because of it. In the case of the VM itself, the original interpreter may have been written for a workstation.
Embedded systems are usually reflected by unusual need for programmer control of the tools used to program the device. For Java to be effective in embedded systems, this programmer control will have to be present. The first line of control will be on the performance aspects of the program. The age-old trading of speed and space won't simply go away because Java is here.
Java has a number of advantages for embedded systems. Using classes to organize the code enforces modularity, and encourages data abstraction. Java has many useful and standardized classes for graphics, networking, simple math and containers, internationalization, files, and much more. This means a designer can count on having these libraries on any (full) implementation of Java.
As mentioned, Java programs are generally more portable than C or C++ programs. For example:
- The sizes of integers, floats, and characters are defined by the language.
- The order and precision of expression evaluation is defined.
- Initial values of fields are defined, and the languages require that local variables be set before use in a way that the compiler can check.
Safety-critical applications will find the following features very useful:
- More disciplined use of pointers, called "references" instead, provides "pointer safety" (no dangling references; all references are either null or point to an actual object; de-referencing a null pointer raises an exception).
- Array indexing is checked, and an index out of bounds raises an exception.
- Using exceptions makes it easier to separate out the normal case from error cases, and to handle the error in a disciplined manner.
It has been argued that even for ROM-based embedded systems, where portability is not an issue, it still makes sense to use a bytecode-based implementation of Java, since the bytecodes are supposedly more compact than native code. However, it is not at all clear if that is really the case. The actual bytecode instructions of a small experimental test class only take 134 bytes, while the compiled instructions for Intel x86 and Sparc take 373 and 484 bytes respectively. However, there is quite a bit of symbol table information necessary, bringing the actual size of the class file up to 1227 bytes. How much space will actually be used at runtime depends on how the reflective symbolic information is represented, but it does take a fair bit of space. Our conclusion is that the space advantage of bytecodes is minor at best, whereas the speed penalty is major.
1.4 Cygnus' Embedded Java Solution
Cygnus is developing an integrated development environment for programming in the C, C++, and Java programming languages, targeting embedded systems, and including a compiler and debugger. This software does not include an interpreter for any of these languages, although it has been designed with consideration given to the possibility of it being used in conjunction with a third-party Java language interpreter. The software has also been designed with consideration given to the possibility of it being used in conjunction with a Real-Time Operating System (RTOS).Cygnus Foundry Java Edition provides a machine-independent Java language solution suitable for high-performance systems development. The requirements for a high-performance system are satisfied by providing a Java-optimizing, ahead-of-time compiler. Optimized ahead-of-time compilation produces code having size and speed comparable to code written in C/C++. At the same time, compatibility with the Java world is afforded, allowing for the mixing and matching of code according to individual system requirements. If the system has a network connection, for example, then the system software may include, in addition to the pre-compiled Java code, a Java Virtual Machine, allowing Java bytecode to be downloaded and run. A coherent model allows for pre-compiled Java code, VM interpreted bytecode, and C/C++ code, to coexist and interact. Preferably, the optimizing ahead-of-time Java compiler is capable of compiling either Java source code or Java bytecode. In this manner, code distributed only in bytecode form may be pre-compiled. A Java stack slot compilation scheme achieves code optimization and overcomes difficulties peculiar to ahead-of-time compilation of Java. In addition, a static layout of Java metadata is created by the compiler, obviating the need to create such a layout at runtime.
2.0 The Java Language
Traditionally Java has been implemented using an interpreter. However, interpreters may not be the best option for use in embedded systems. Compilation might offer better performance for embedded systems than an interpreter.2.1 Java Interpretation
The traditional method of implementing Java is through an interpreter that implements the Java virtual machine (VM). A compiler is used to compile Java source code into ".class" files containing
machine-independent bytecode instructions. These
".class" files are then downloaded and interpreted by the
VM. Common services may be offered in the form of class libraries, or
".so" shared library files. Class libraries provide
services to the Java VM and to the bytecode program, in particular
basic language support and extended functionality. A runtime library
provides low-level garbage collection (GC) and thread support and runs
directly on top of the machine hardware. This method is shown in
Figure 1.
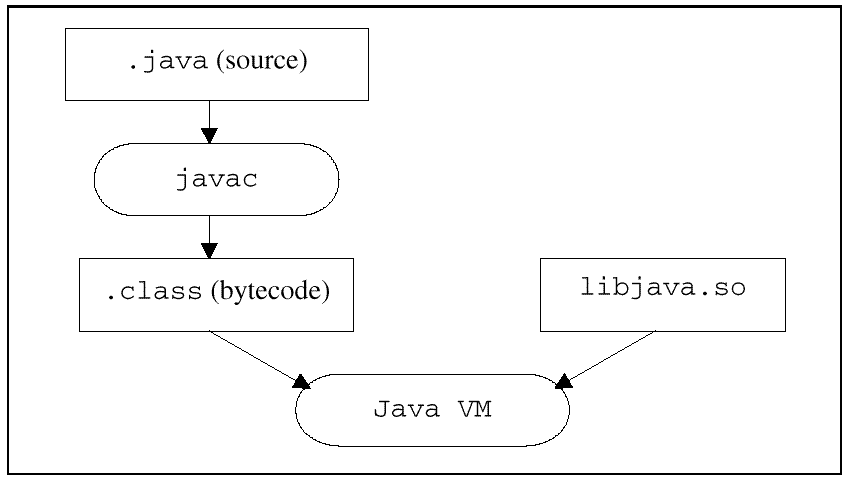
Figure 1: Interpreter based Java implementation
The Java Virtual Machine
The Java VM is conceptually a stack machine. The instructions interpreted by the VM manipulate data stored within "stack slots."The executable content of a bytecode file contains a vector of bytecode instructions for each method. The bytecodes are instructions for the VM, which has some local variable registers and a stack used for expression evaluation. The first few local variables are initialized with the actual parameters. Each local variable or stack "slot" is a word big enough for a 32-bit integer, a float, or an object reference (pointer). Two slots are used for 64-bits doubles and longs.
The slots are not typed; i.e., at one point, a slot might contain an integer value, and, at another point, the same slot might contain an object reference. However, you cannot store an integer in a slot, and then retrieve the same bits reinterpreted as an object reference. Moreover, at any given program point, each slot has a unique type that can be determined using static data flow. The type may be "unassigned," in which case you are not allowed to read the slot's value. These restrictions are part of the Java security model, and are enforced by the Java bytecode verifier.
The interpreter reads the bytecode stream and performs the operations specified. The simplest VM is known as a bytecode interpreter. Interpreted code is generally slower than an equivalent program written in a compiled language, and Java is no different in this regard.
There have been many improvements in the approaches for improving the performance of interpreters. A common one today is to include a relatively simple compiler inside the runtime of the VM. Rather than interpreting the bytecode programs, the classes and their accompanying methods are compiled on the fly inside the VM, and the compiled representation is then executed whenever the method is called. This is known as a Just In Time (JIT) compiler.
Problems with Interpretation in Embedded Systems
The biggest problem with interpreters is speed: it is not unusual for an interpreted program to run between 10 and 20 time slower than its compiled counterpart. A JIT-based interpreter can, however, speed up program execution, sometimes quite dramatically. Running a compiler inside a VM costs execution time somewhere. This loss of execution time is often most noticable in the start up time for an application. In addition, it is difficult to generate high quality code using a JIT. During the execution of the user's program, it is not usually practical to invest either the time or perhaps the space to do the sophisticated optimizations that are common in modern compilation systems. Only simple register allocation and "peephole optimizations" are practical.
Also during JIT compilation, before code is executed, considerable
time may be spent initializing structures and tables. A Java
".class" file includes substantial "metadata" describing
the class. This metadata cannot be efficiently accessed from the
class file itself. Instead, the Java runtime environment must read
the metadata, and from that metadata, build an extensive data
structure that describes each class with its fields and methods.
Building these data structure increases startup time.
The JIT machinery may be costly in other system resources such as memory. Depending on the strategy implemented, there may be two copies of the code, one in the bytecode representation and the other in the native representation. In addition, the overall size of the VM is usually significantly larger as a result of the inclusion of the JIT compiler.
While JIT compilers have an important place in a Java system, for frequently used applications it is better to use a more traditional ahead-of-time or batch compiler. While many think of Java as primarily an Internet/Web language, others are interested in using Java as an alternative to traditional languages such as C++, provided performance is acceptable. For embedded applications, it makes much more sense to pre-compile the Java program, especially if the program is to be in ROM.
2.2 Java Compilation
Many of the problems with using Java in embedded systems can be solved by the use of an optimizing, ahead-of-time compiler. Optimized ahead of time compilation produces code with comparable size and speed as code written in C/C++.Using optimizing ahead-of-time compilation eliminates many of the drawbacks of using the Java language in embedded systems. It increases performance since no interpretation has to occur. And it also reduces the memory footprint since only one copy of the program must be maintained in memory and memory consumed by the possibility complicated JIT based interpreter is no longer needed.
The GNUPro Compiler
The foundation of the embedded tools developed by Cygnus is the GNUPro compiler (GCC), which contains machine-specific compiler "back-ends" for more than 100 embedded processors connected to a common "front-end," enabling code written in C/C++ to be compiled for any of the supported processors. The GNUPro compiler runs on both Windows and Unix host platforms.The GNUPro compiler package includes:
- Build time components:
- GCC - C to Assembly Compiler
- G++ - C++ to Assembly Compiler
- GAS - Machine Language Assembler
- LD - Object File Linker
- GDB - Source Level Debugger
- Instruction Set Simulator (for certain targets only)
- Runtime components:
- Standard C Programming Library
- Standard C Header Files
- Standard C++ Programming Library
- Standard C++ Header Files
The GNUPro Java Compiler
Cygnus is building a Java programming environment based on a conventional compiler, linker, and debugger, by adding Java language support to the existing GNUPro programming tools. The GNUPro tools have been ported to just about every chip in use in the industry today, including many chips used only in embedded systems, resulting in a uniquely portable Java system. Figure 2 outlines the compilation process.
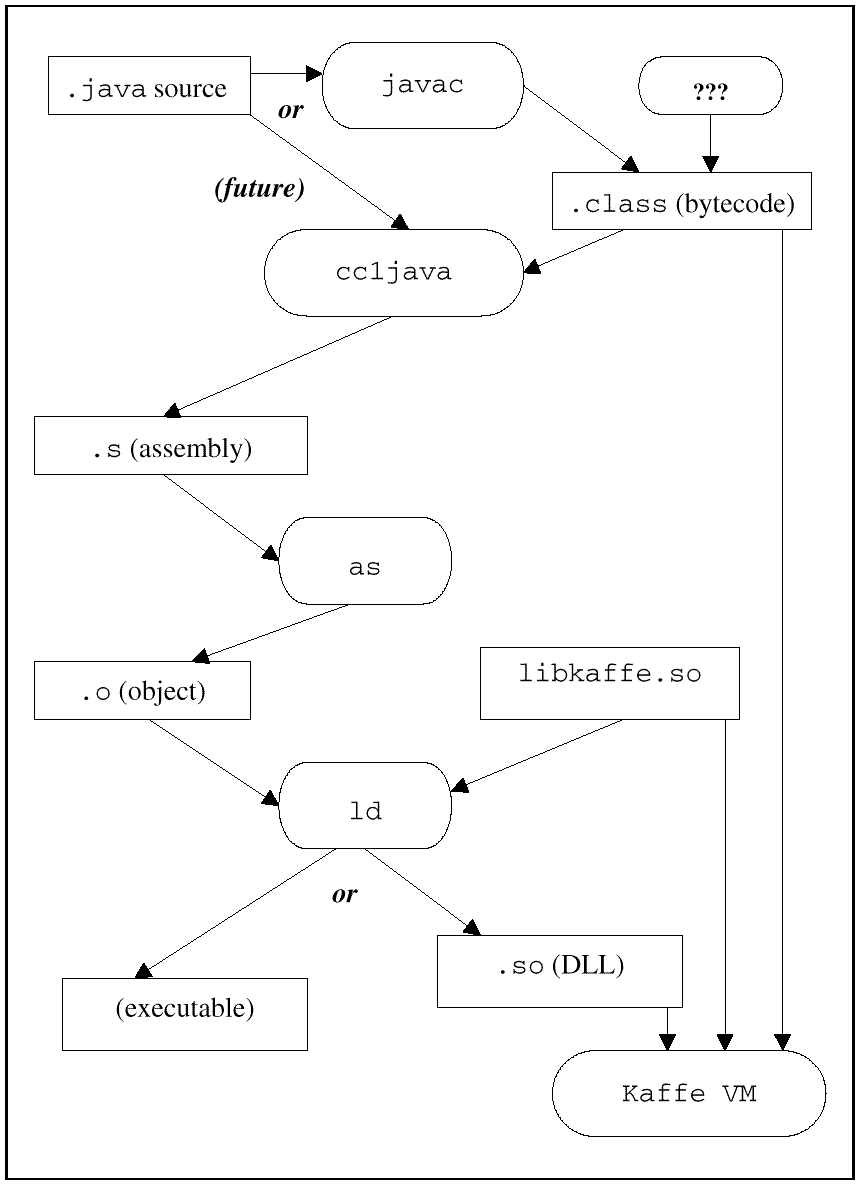
Figure 2: Compiled Java
The front-end, called jc1, translates Java bytecode or
Java source code into the GCC intermediate node format called "tree
nodes." Such trees are later processed by the middle and back-ends of
the compiler into machine code, taking benefit of the extensive GNUPro
optimization schemes and its broad CPU support. jc1 also
provides the back-end with information on how to generate the compiled
class reflective data used by the runtime system during execution of
the compiled code.
The most unusual aspect of jc1 is that its "parser" reads
either Java source files or Java bytecode files. It is important that
jc1 be able to read bytecodes in addition to Java source
for the following two reasons:
- Some third-party Java libraries may be distributed in Java bytecode form without source.
- It is the natural way to get declarations of external classes. In this respect, a Java bytecode file is like a C++ pre-compiled header file.
From the start, the intent has been solid integration with the code generated by the C and C++ versions of the compiler. Exception handling mechanisms will be shared, as well as a high degree of compatibility in object representation. This is necessary for a reliable high performance coexistence between the languages.
In addition to being able to compile Java source code to machine code, and Java bytecode to machine code, the compiler is able to compile Java source code to bytecode. This will allow the compiler to also be used in conjunction with a third-party VM.
Compilation Methodology
Much of the work of the compiler is the same whether we are compiling from source code or from bytecodes. For example, emitting code to handle method invocation is the same either way. When we compile from source, we need a parser, semantic analysis, and error checking. On the other hand, when parsing from bytecodes, we need to extract some higher-level information from the lower-level bytecodes.As part of the compilation process it is necessary to do an analysis for each program point to determine the current stack pointer, and the type of each local variable and stack slot.
Stack Slot Compilation
Internally, GCC uses two main representations. The tree representation is at the level of an abstract syntax tree, and is used to represent high-level (fully-typed) expressions, declarations, and types. The RTL (Register Transform Language) form is used to represent instructions, instruction patterns, and machine-level calculations in general. Constant folding is done using trees; otherwise most optimizations are done at the RTL level.The basic strategy for translating Java stack-oriented bytecodes is that we create a dummy local variable for each Java local variable or stack slot. These are mapped to GCC "virtual registers," and standard GCC register allocation later assigns each virtual register to a hard register or a stack location. This makes it easy to map each opcode into tree nodes or RTL to manipulate the virtual registers.
Stack slot compilation is the process of mapping instructions whose target is the stack machine constituting the Java VM to register-specific instructions whose target is a real processor. Within the compiler, this mapping is a two step process. First, within the compiler stack slots are mapped to "virtual registers". Second, these virtual registers are mapped to physical registers or to memory locations in a function call frame. The mapping must observe type constraints imposed by the compiler and should also produce efficient, optimized code. A simple one-to-one mapping between stack slots and virtual registers does neither. Consider the example shown in Table 1, in which a register value ("Register 1") is incremented by a constant value (5). In the example, vreg11, vreg50 and vreg51 are virtual registers within the compiler. The simple mapping shown does not take advantage of possible optimizations. An optimizer may be run subsequently during a separate pass. Such an approach, however, is inconvenient and time-consuming.
| Java | Bytecode | Simple Translation |
|---|---|---|
x = 5 + x
|
iconst 5
|
vreg50 = 5
|
This simple compilation process outlined has several problems:
- We would like to do constant folding, which is done at the tree level. However, tree nodes are typed.
- The simple-minded approach uses lots of virtual registers, and
the code generated is very bad. Running the optimizer (with the
"
-O" flag) fixes the generated code, but you still get a lot of useless stack slots. It would be nice to not have to run the optimizer, and if you do, not make unnecessary work for it. - The RTL representation is semi-typed, since it distinguishes the various machine "modes" such as pointers and different-sized integers and floats. This causes problems because a given Java stack slot may have different types at different points in the code.
Using a separate virtual register for each machine mode solves the
last problem. A stack slot is mapped not to a single virtual register
but to a "family" of virtual registers, one for each machine mode.
For example, for local variable slot 5 we might use
vreg40 when it contains an integer, and
vreg41 when it points an object reference. This is safe,
because the Java verifier does not allow storing an integer in an
object slot and later reusing the same value as an object reference or
float. An example mapping is shown in Table 2. Table 2 is
implemented as a sparse data structure, filled out by the compiler
only as needed.
| Machine Mode | Used for Java Type | JVM Stack Slots | JVM Local Registers
(Incoming Arguments and Local Variables) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | ... | max_vars-1 | 0 | 1 | ... | max_stack-1 | ||
| SI
(Single Integer) | int, short, boolean, byte, char | vreg50
| vreg51
| vreg11
| |||||
| DI
(Double Integer) | long | ||||||||
| SF
(Single Float) | float | ||||||||
| DF
(Double Float) | double | ||||||||
| P
(Pointer) | all object references | vreg10 | |||||||
Code efficiency is achieved by modeling the Java stack as a stack of
tree nodes, and not storing the results in their "home" virtual
registers unless we have to. Thus internally the compiler executes
the following code for iadd:
tree arg1 = pop_value (int_type_node);
tree arg2 = pop_value (int_type_node);
push_value (fold (build (PLUS_EXPR, int_type_node, arg1, arg2)));
The build function is the standard GCC function for
creating tree nodes, while fold is the standard function
for doing constant folding. The functions pop_value and
push_value keep track of which stack location corresponds
to which tree node. From the tree node representation built up by the
compiler front-end, the back-end eventually generates actual code.
This above strategy works for straight-line code (i.e., within a basic block). When we come to a branch or a branch target, we have to flush the stack of tree nodes, and make sure the value of each stack slot gets saved in its "home" virtual register. The stack is usually empty at branches and branch targets, so this does not happen very often. Otherwise, we only emit actual RTL instructions to evaluate the expressions when we get to a side-effecting operation, such as a store or a method call.
Since virtual registers are allocated only as needed, fewer virtual registers are used, resulting in better code. The benefit is also obtained of constant folding and of existing machinery for selecting the right instructions for addition and other expressions. The result is that code is generated using substantially the same mechanisms used by the GNUPro C and C++ front ends. Similar code quality may therefore be expected.
Note from these examples that the Java stack exists only at compile time. There is no Java stack, Java stack pointer, or stack operations in the emitted code.
Class Metadata
Compiling the executable content is only part of the problem. The Java runtime also needs an extensive data structure that describes each class with its fields and methods. This is the "metadata" or "reflective" data for the class. The compiler has to somehow make it possible for the runtime system to correctly initialize the data structures before the compiled classes can be used. If we are compiling from bytecodes, the compiler can just pass through the metadata as they are encoded in the class file.It is inconvenient if the metadata and the compiled code are in different files. The runtime should be able to create its representation of the metadata without having to go beyond its address space. For example reading in the metadata from an external file may cause consistency problems, and it may not even be possible for embedded systems.
A possible solution is to emit something like:
static const char FooClassData[] = "\xCa\xfe\xba\xbe...";
static {
LoadClassFromByteArray(FooClassData);
Patch up method to point to code;
}
The code marked static is compiled into a dummy function
executed at program startup. This can be handled using whatever
mechanism is used to execute C++ static initializers. This dummy
function reads the metadata in external format from
FooClassData, creates the internal representation, and
enters the class into the class table. It then patches up the method
descriptors so that they point to the compiled code.
This approach works, but it is rather wasteful in terms of memory and
startup time. We need space for both the external representation (in
FooClassData) and the internal representation, and we
have to spend time creating the latter from the former.
By having the compiler directly create the internal representation required by the runtime environment, we can both reduce the amount of code required and improve runtime performance.
The compiler statically allocates and initializes the internal data structures. This means the actual initialization needed at runtime is very little; most of it is just entering the metadata into a global symbol table.
Consider the following example class:
public class Foo extends Bar {
public int a;
public int f(int j) { return a+j; }
};
That class compiles into something like the following:
int Foo_f (Foo* this, int j)
{ return this->a + j; }
struct Method Foo_methods[1] = {{
/* name: */ "f";
/* code: */ (Code) &Foo_f;
/* access: */ PUBLIC,
/* etc */ ...
}};
struct Class Foo_class = {
/* name: */ "Foo",
/* num_methods: */ 1,
/* methods: */ Foo_methods,
/* super: */ &Bar_class,
/* num_fields: */ 1,
/* etc */ ...
};
static {
RegisterClass (&Foo_class, "Foo");
}
Thus, startup is fast and does not require any dynamic allocation.
Static References
A class may make references tostatic fields and methods
of another class. If we can assume that the other class will also be
jc1-compiled, then jc1 can emit a direct
reference to the external static field or method just
like a C++ compiler would. That is, a call to a static
method can be compiled as a direct function call. If you want to make
a static call from a pre-compiled class to a known class that you do
not know is pre-compiled, you can try using extra indirection and a
"trampoline" stub that jumps to the correct method.
A related problem has to do with string constants. The language specification requires that string literals that are equal will compile into the same String object at runtime. This complicates separate compilation, and it makes it difficult to statically allocate the strings. To deal with this, we need to either compile references to string literals as indirect references to a pointer that gets initialized at class initialization time, or modify the linker.
Linking
Thejc1 program creates standard assembly files that can
be processed by the standard unmodified GNUPro assembler. The
resulting object files can be placed in a dynamic or static library,
or linked (together with the runtime system) into an executable using
a standard linker. The only linker extension we really need is
support for static initializers, but we already have that since the
GNUPro compiler already supports C++.
While we do not need any linker modification, the following linker enhancements may be desirable:
- Java needs a lot of names at runtime --- for classes, files,
local variables, methods, type signatures, and source files. These
are represented in the constant pool of "
.class" files asCONSTANT_Utf8values. Compilation removes the need for many of these names because it resolves many symbolic field and method references. However, names are still needed for the metadata. Two different class files may generate two references to the same name. It may be desirable to combine them to save space. This requires linker support. The compiler could place these names in a special section of the object file, and the linker could then combine identical names. - The runtime maintains a global table of all loaded classes, so it can find a class given its name. When most of the classes are statically compiled and allocated, it is reasonable to pre-compute the static part of the global class table. One idea is that the linker could build a perfect hash table of the classes in a library or program.
Performance
It is too early to have any solid performance figures for the GNUPro Java compiler technology. Early projections, however, are very encouraging.In one test, for a small test method, the GNUPro compiler generated 10 instructions, whereas a JIT compiler we examined produced around 35 or 40 instructions. The higher number of instructions associated with the JIT compiler reflected the fact that it was able to perform fewer optimizations than an ahead-of-time compiler.
In another test, a small test program took 16 seconds to execute. When the same program was dynamically compiled using a JIT it took 26 seconds. Using Sun's JDK 1.1 it took 88 seconds.
Most recently, we have started experimenting with larger applications. The Linpack benchmark is a well-known benchmark that is intended to be indicative of application performance when solving systems of linear equations. On the Java version of the Linpack benchmark, we are currently seeing compiled Java code offer a performance advantage of 6 or 7 times the speed of Sun's JDK 1.1.
Additional performance gains may be possible by taking advantage of specific compiler features we intend to introduce. In particular, we intend to give the programmer the ability to disable runtime checking for array bounds violations, and so on. This both reduces code size and increases performance, although the resulting system is no longer strictly in accordance with the Java language specification. On the Linpack benchmark, disabling these runtime type checks boosted performance to 8 or 9 times the speed of Sun's JDK 1.1.
Cygnus has established the following long term Java performance goals:
- No more than 30% slower than C++.
- 100 fold performance penalty acceptable for dynamic code.
- Performance optimizations: able to disable array bounds checking and so on.
Problems with Compilation
Compilation alone is insufficient. The Java language includes a facility for turning an array of bytes into executable bytecode. It is this facility that makes it possible for Java code to be transferred over a network, and for Java applications to be dynamically upgraded in the field. A pure ahead-of-time compilation system is, however, unable to provide this capability.There are many embedded systems that do not need this facility. There are, however, some embedded systems were such facilities are important. Set-top boxes are a good example. In such systems, it typically isn't the entire system that needs to be able to be dynamically downloaded, but just a small piece of functionality. Often the vast majority of the system can be pre-compiled, but a small piece of functionality still needs to be able to be dynamically updated.
2.3 Combined Systems
To solve the problem of dynamic code, while providing the performance advantages of an ahead-of-time compiler, it is necessary to combine the interpreter and compiler based approaches. As much code as possible is compiled to machine code ahead-of-time for the maximum performance advantage. A VM interpreter included as part of the system executes any remaining Java code in bytecode form at runtime.For embedded systems where dynamic code is not present, a VM interpreter isn't necessary, and there is no need to include it in the resulting embedded system. The price of the VM interpreter's memory footprint will only be paid in those cases where it is necessary.
As part of the current work, Cygnus does not intend to develop an interpreter for constructing a combined system. Cygnus does, however, intend to ensure that it will be possible to produce a combined system by combining the compiler it develops with a third-party Java VM not developed by Cygnus.
An important aspect of building a combined system is how the two Java subsystems interoperate. This is covered in detail later in this document.
2.4 Source Language Character Set Issues
The Java language specification mandates the internal use of the Unicode character set. Irrespective of the advantages or disadvantages of Unicode, it isn't possible to avoid the internal use of Unicode for characters in Java without major changes to the Java language specification.Fortunately Java has a wide range of input, output, and conversion methods that make it relatively easy to hide the internal encoding of characters from the external demands placed upon embedded applications. Critical to transparency of this in embedded applications, and an area in which Cygnus will be paying special attention, is ensuring the space taken up by any necessary translation tables in the resulting system is kept as small as possible.
Separate from, and more contentious than the issue of the internal encoding of characters, is the issue of the encoding scheme the compiler assumes for Java source files. For C and C++ the encoding scheme assumed by the compiler has never really mattered. With Java, the encoding scheme assumed is significant.
Most C and C++ compilers assume the input source files are streams formed from byte encoded ISO 8859-1 characters. Whether this is actually true or not doesn't really matter. JIS, Shift-JIS, or EUC encoded characters can also be included in the byte stream inside source code comments and strings, and so long of none of the bytes appears to the compiler as a string or comment terminator, the compiler would be oblivious to this. With the JIS, Shift-JIS, and EUC encodings there isn't the risk of bytes being interpreted as a string or comment terminator, so no problems occur. At runtime the system might treat a single JIS, Shift-JIS, or EUC character as a sequence of characters, but this has no real impact. Also note that most importantly none of the JIS, Shift-JIS, and EUC byte sequences contain the null byte, which is used in C and C++ to signify the end of a string. The system simply passes JIS, Shift-JIS, and EUC encoded characters straight through transparently, not even realizing their actual use.
For Java, in order to take advantage of character set handling features of the language, it is necessary to correctly translate encoded character strings on input to their actual Unicode character encodings. This, however, destroys the ability to transparently pass characters straight through the system. An explicit programmer-controlled phase of mapping back to JIS, Shift-JIS, or EUC encoded characters would be necessary upon output of a string.
Cygnus proposes to offer two source file modes, and to allow developers to choose between these modes. In the first mode the compiler will recognize JIS, Shift-JIS, and/or EUC encoded characters embedded within strings, and convert them at compile time to their Unicode equivalents. This is compatible with the Java language, and allows the programmer the ability to take full advantage of the Java language methods for performing operations on characters. It has the side effect of requiring explicit programmer intervention and runtime tables when outputting characters in JIS, Shift-JIS or EUC encoded formats. In the second mode, the compiler will treat the input stream as an ISO 8859-1 encoded byte stream, and will in effect pass JIS, Shift-JIS, and/or EUC encoded characters straight through it. This will prevent the programmer from having to deal with encoding issues on output, and potentially substantially reduce the size of otherwise needed runtime tables. However, the programmer will not then be able to use the Java language character class methods on actual characters, but only on essentially meaningless encoded representations of characters.
Cygnus understands the difficulties associated with the Java character set issues. For the internal encoding, it is necessary to use Unicode. For Java source files, however, the encoding method or methods the compiler should use are less clear. Cygnus welcomes input and advise on both the importance of this issue, and the best way to solve it.
3.0 The Java Runtime
To run a compiled Java program requires a suitable Java runtime environment. This is, in principle, no different from C++ which requires an extensive runtime library, as well as support for memory allocation, exceptions, and so on. However, Java requires more runtime support than "traditional" languages. Java also requires support for garbage collection, threads, type reflection, and all the primitive Java methods.3.1 Memory Size
In addition to maximizing execution speed, minimizing memory consumption is equally worthy of attention in embedded systems. In the standard Java model, in addition to space needed for the user code, there is also a substantial body of fixed code for the Java VM and runtime environment. This code includes, for example, standard libraries, code for loading new classes, a garbage collector, and a possible VM interpreter.Some applications may need access to dynamically loaded classes, reflection, and a large class library. Other applications may need none of these, and cannot afford the space requirements of those features. In a memory-tight environment, it may be desirable to leave out some of this support code. For example, if there is no need for loading new classes at runtime, the code for reading class files and interpreting bytecodes may be omitted.
Depending on a conventional linker to select only the code actually
needed does not work, since a Java class can be referenced using a
runtime String expression passed to the Class.forName
method. If this feature is not used, then a static linker can be
used.
The Java runtime needs to have access to the name and type of every
field and method of every class loaded. This is not needed for normal
operation. However, a program can examine this information using the
java.lang.reflect package. Furthermore, the Java Native
Interface (JNI) works by looking up fields and methods by name at
runtime. Using the JNI thus requires extra runtime memory for field
and method information. Since the JNI is also quite slow, an embedded
application may prefer to use a lower-level but less portable Native
Interface. Different applications may also want different algorithms
for garbage collection or different thread implementations. This all
implies the need for a configuration utility, so one can select the
features one wants in a VM, much like one might need to configure
kernel options before building an operating system.
Cygnus has established the following long term Java memory size goals:
- Minimal application: 32k ROM, 8k RAM.
- Minimal application with dynamic code: 128k ROM, 32k RAM.
- Performance optimizations: able to disable use of specific subsystems.
3.2 Low-level Interfaces
The runtime provides a set of services to the application using it. Many of these services the runtime is able to provide internally. To provide other services, though, it is necessary for the runtime to either communicate with another subsystem, or to access the underlying hardware. To facilitate this, a set of low-level internal interfaces need to be defined between the runtime and the hardware and software environment within which it resides.It might be possible to code directly to the raw hardware. However, defining a clean set of abstractions makes it easier to support additional targets, and to develop code for real devices and systems with their differing hardware characteristics, rather than just develop applications for execution on evaluation boards. The following low-level interfaces should be defined:
- interface to platform memory allocation
- interface to periodic interrupt source (optional)
- interface to time of day and timing facilities
- interface to target environment threading primitives (optional)
- runtime startup interface
- debugging interface
In cases where compiled code is required to coexist with third-party VM code, clearly and cleanly defining these interfaces is vital. Having a well defined low-level interface will make it much easier for a third-party to integrate the two Java systems.
3.3 Threading
Unlike C and C++, the Java language includes threads as a primitive language feature. Consequently, runtime support for threads needs to be provided.The provision of runtime support for threads, while needing to be done at a low-level, and probably in a mixture of C and assembly language, is unlikely to prove difficult. For simplicity and flexibility the necessary routines will probably be coded directly, rather than attempting to adapt an existing threads package.
Despite being multi-threaded, we will not be providing any support for multi-processor systems. Multi-processor support would require support for fully pre-emptive threading, which is not something that can be initially supported.
Possibly, the most difficult aspect of thread support isn't in the support of threads in Java itself, but the support of interactions between Java threads and other systems. These other systems include garbage collection, C and C++ code, C and C++ library code, and any third-party Java interpreter and its threads. Our analysis of these issues is currently at a preliminary stage.
3.4 Garbage Collection
The Java programming language doesn't provide an imperative way to indicate that an object, corresponding to an allocated chunk of memory, can be thrown away. Instead, the Java runtime relies on garbage collection to automatically identify and reclaim objects no longer in use.
Programmers used to traditional
malloc/free-style heap management tend to be
skeptical about the efficiency of garbage collection. It is true that
garbage collection usually takes a significant toll on execution time,
and can lead to large unpredictable pauses. However, it is important
to remember that is also an issue for manual heap allocations using
malloc/free. There are many poorly written
malloc/free implementations in common use,
just as there are inefficient implementations of garbage collection.
There are a number of incremental, parallel, or generational garbage
collection algorithms that can provide performance as good or better
than malloc/free. What is difficult, however, is
ensuring that pause times are bounded --- i.e., a small limit on the
amount of time the new method can take, even if garbage
collection is triggered. The solution is to make sure to do a little
piece of garbage collection on each allocation. Unfortunately, the
only known algorithms that can handle hard real-time either require
hardware assistance or are inefficient. However, "soft" real-time can
be implemented at reasonable cost.
Techniques to automatically reclaim portions of memory allocated by an application no longer in use have been extensively studied for more than three decades. While mostly used in the implementation of languages like Lisp, garbage collection has made its way over the past ten years into more popular programming languages such as C, C++ (as libraries without language support) and now Java. The lesson learned over thirty years of research and development is that the efficiency of garbage collection algorithms depends on many factors. One is the hardware of the targeted platform: its CPU type, the amount of memory available and the availability of memory management hardware support. Another factor is the type of runtime system (compiled or interpreted) and the level of support it provides for memory allocation, supervised or unsupervised. Finally, factors depending on the application itself, notably the memory usage patterns like memory cells connectivity, relative size and live span of allocated objects are also relevant. Once these factors have been taken into consideration, the suitable garbage collection algorithms should be reviewed in order to take into account their processing costs, the space overhead they impose both for allocated data and code size, and the performance degradation they incur as the heap fills up.
As is the case for other programming languages and execution environment, designing and implementing a garbage collector suitable to the use of the Java language in embedded systems is not an easy task. It requires a deep analysis of a variety factors ranging from the hardware in use to the dynamic of the application to run on the embedded system. Garbage collection truly is a "no silver bullet" problem.
Garbage Collection Algorithms
Garbage collection relies on the observation that a previously allocated memory location that's no longer referenced by any pointers can't be reached again by the application and is therefore reclaimable. The role of a garbage collector is to identify and recycle these unreachable allocated memory chunks. There are two families of garbage collecting techniques, reference counting and tracing, which yield three main algorithms.Reference Counting
Reference counting keeps track of the number of references to a memory cell. The cell is considered reclaimable whenever this number reaches zero. The compiler or the runtime system is responsible for adjusting the reference count every time a pointer in updated or copied. The main advantage of reference counting is that the computational overhead is distributed throughout the execution of the program, which ensures a smooth response time. Reclaiming an isolated cell doesn't imply accessing other cells, and there are optimizations that reduce the cost of deleting the last reference to an entire group of cells, which otherwise depends on the size of the group of cells. The major weakness of reference counting is its inability to reclaim cyclic structures such as doubly-linked lists or trees featuring leaf nodes with pointers back to their roots. A second problem with reference counting is it typically has a high computational overhead.Tracing Algorithms
Reachable (or live) memory locations are those that are directly or indirectly pointed to by a primordial set of pointers called the roots. The two kinds of tracing algorithms "mark and sweep" and "copying" both start from the roots and examine the allocated memory cells' connectivity.Mark and Sweep
Mark and sweep takes place whenever the amount of free memory goes below a certain threshold, it marks active memory cells and then sweeps through the allocated cells. The active cells are those that are reachable through pointer reference, starting with the roots. At the end, any unmarked cells are returned to the available memory pool. The advantage of this approach is its ability to reclaim cyclic data structures. But if implemented as described, it may not be acceptable for an application with some real-time constraints.Copying
The copying algorithm uses a heap divided into halves called semi-spaces. One, the current space, is used for memory allocation. When garbage collection takes place, memory cells are traced from the current space and copied into the second one. When done, the second space contains only live non-garbage cells and becomes the new active space. The cells get automatically compacted as a result of this process. The unreachable garbage cells were not copied and are thus naturally reclaimed. The copying algorithm ensures fast allocation of new cells and reduces fragmentation. On the other hand, it immediately divides by two the size of memory available to the application and touches all the living memory cells during the copy algorithm, which may lead to a considerable number of page faults on a system using pagination.Refinements and Implementations
Several refinements to those three algorithms have been proposed in an attempt to overcome their limitations and weaknesses or to optimize their execution. These refinements imply making choices on implementation details such as how roots are identified and how the execution of the collector is scheduled.For example, reference counting can be optimized to reduce how often reference count fields have to be updated and to reduce the size of the reference count field. It can also be modified to detect pointers that are part of a cycle or can even be combined with a tracing algorithm in order to reclaim cyclic data.
Incremental tracing algorithms have been implemented so as to reduce the latency induced when the memory is scanned during the mark and sweep phases. This balances the execution of the collector over the lifetime of the application. The resulting synchronization problems can be solved by installing read or, preferably, write barriers that tell the garbage collector that a given cell should be reconsidered before really being reclaimed. This requires the compiler or the runtime system to update the status of a cell whenever a pointer to it is read or written.
There are two types of tracing garbage collectors. Accurate or exact collectors are able to distinguish pointer from non-pointer data. Conservative collectors on the other hand consider every word they encounter a potential pointer. This affects the way pointers are identified within the location where roots can be found (registers, stack, and static areas) and the way they scan cells looking for pointers to other cells. A conservative garbage collector may misidentify a word as a pointer and thus retain memory cells that are in fact garbage. The need to consider every word as a potential pointer means that a fully conservative garbage collector can't be a fully moving/compacting collector. Conservative collectors can be altered to be mostly copying: objects that are solely accessible from other heap-allocated objects are copied. They are deployed on systems where no cooperation from the compiler or the runtime system is expected to help the collector tell whether a word is a pointer or not.
Finally, tracing algorithms can be implemented using a generational strategy. Two or more different regions of the heap are used to store and collect memory cells. The region used for a particular memory cell depends upon its life span. Generational strategies aim at optimizing the garbage collection of young and supposedly short-lived objects without having to waste time unsuccessfully dealing with long-lived objects. Youngest areas are scanned more frequently, reclaiming more garbage with less effort.
Garbage Collection and Java
Garbage collection doesn't alter the behavior of an application written in Java. The only exception is for the classes that declare afinalizer method. Finalizers are executed right before
objects found to be garbage are discarded, giving a chance to the
developer to explicitly release other resources they lock. Tricky
finalizers may resuscitate an object by installing a new reference to
it, but finalizers are executed only once. This guarantees that
objects may be brought back to life only once. Beginning with JDK
1.1, data belonging to classes is also garbage collected, allowing
unused classes to be automatically discarded.
The initial set of roots of a Java runtime are contained in static
globals, stack locations, and registers. Up until JDK 1.1.4, Sun's
JDK implementation of garbage collection was a partially conservative
compacting mark and sweep algorithm. It makes conservative assumption
when the native stack is scanned but the Sun implementation allows the
Java heap and stack to be scanned in a non-conservative way. The
algorithm compacts the heap when it substantially reduces its
fragmentation. It takes advantage of the fact that an object
reference is a handler to the object's data and methods to keep the
cost of relocation to a low. The garbage collection code is executed
in a separate thread when the system runs out of memory or when
System.gc is explicitly invoked. The collector may also
run asynchronously when it detects that the system is idle, but this
can require some support from the native thread package. In any case,
execution of the garbage collector halts all other application threads
and scans the entire heap.
Algorithms for Embedded Java Systems
Today's 32-bit embedded systems encompass a broad range of memory requirements. On the low end, a simple point of sale terminal might require 128K of ROM and 32k of RAM. At the high end, a sophisticated set top box might require 16M of ROM and 4M of RAM. These requirements govern the design and the implementation of the garbage collector, and make it a central part in the process of adapting the Java platform to embedded systems.Adapting Java garbage collection to embedded systems requires taking into account four different issues: the nature of the runtime environment, the hardware characteristics and limitations of the embedded platform, the expected performances (acceptable overhead and maximum pause times), and the way in which critical memory situations need be handled.
The runtime environment will directly influence the way roots are identified. An interpreted or semi-compiled (JIT) environment still gets a chance to clearly make references identifiable so the Java heap and the Java stack can be scanned non-conservatively. One the other hand, the pre-compiled approach --- like the one being currently developed at Cygnus --- needs to rely on conservative scanning, unless additional information is made available to the runtime by a cooperative compiler.
The hardware characteristic of an embedded system is that memory, both RAM and ROM, is a scarce resource. It rules out, in most of the cases, all copying and generational algorithms and prevents sophisticated solutions like adaptive or cooperative collectors because of the amount of ROM required to hold several collectors. It also puts the emphasis on minimizing the amount of memory required by the collector, which most noticeably includes the space used to mark the status of allocated memory cells. Reference counting requires the count field of an allocated object to be roughly the same size as a pointer or some other value that can represent all valid addresses of the system. This field has to remain tied to the object. On the other hand, information tags required by a mark and sweep range from a minimum of 1 bit to several for three colors or pointer reversal marking algorithms.
Most embedded systems don't provide paged virtual memory, which implies that accessing a random portion of the memory has essentially a fixed cost, although it may disrupt the cache. This diminishes the impact of the mark-sweep and the space costly copying collectors that visit all live cells before reclaiming the dead ones. On the other hand, this also means the heap can't be expanded.
Non-disruptive Garbage Collection
As previously mentioned, an embedded application running Java has a strong chance of being interactively operated by a user. This demands a fast, non-disruptive garbage collector that also provides predictable performance for future memory allocation. The garbage collector should be non-disruptive so it can periodically perform partial garbage collection of the memory. This periodic running of the garbage collector needs to be sufficient to normally be able to prevent the need to run the garbage collector when a cell is allocated. However, no noticeable slow down should occur in the extreme case that the collector is forced to run.
Enhancement of predictability can be achieved through improvements in
locality so that the low-level operation of reserving memory doesn't
have to scan the heap trying to find sufficient free memory for an
indeterminate amount of time. It should also be guaranteed to succeed
if enough free memory is known to be present. It is unacceptable for
an embedded system to have a memory allocation failing because the
fragmentation of the heap prevents the allocator from finding a memory
block of a sufficient size. Locality can be improved by compacting
the heap. During this operation, cells can be moved in such a way
that the order of their allocation is retained using a technique
called "sliding," or in a way such that a cell pointed to by another
is moved to a close adjacent position, called "linearizing." In
addition to the copying algorithm which compacts the heap as a
side-effect of copying a live cell from one semi-space to another one,
there are several compacting mark-sweep algorithms, also called
mark-compact in this case, with complexities ranging from
O(M) to O(M log M), where M is
the size of the heap. Note that conservative scanning imposes
restrictions on objects that can be moved.
To be able to provide non-disruptive garbage collection, it is necessary to use an incremental algorithm that runs for a fixed amount of time and ensures that further memory allocation requests won't fail. Unfortunately, real-time algorithms usually rely on additional processors or huge amounts of memory so that they can run copying type collectors. The Wallace-Runciman algorithm combines mark-during-sweep where portions of the heap are marked and then swept as the mark phase works on the next region, and stack collect, a modified mark-sweep where states of the marking phase are pushed on a stack. Stack-collect avoids mark-during-sweep worst-case execution time behavior, which is quadratic to the size of the heap. This algorithm has a small 3 bits per cell overhead, can operate with very small stack depth, and its execution time is bounded. Unfortunately, its execution time accounted for 30%-45% of an application runtime in early implementations, targeting a functional language and assuming a heap exclusively made of binary cells.
Baker's incremental copying algorithm is a popular real-time collector that doesn't really fit in a embedded environment. It requires at least twice the minimum amount of memory in order to be implemented. Wilson and Johnstone devised an incremental non-copying implicit reclamation collector that meets real-time constraints. It uses a write barrier to mark pointers to non-examined objects stored in cells that have already been examined so they are later re-examined by the collector. This is combined with a non-copying implicit reclamation strategy where unreached objects don't need to be traversed in order to be reclaimed. The main cost resides in the necessity of maintaining data structures used to keep track of reachable cells in order to deduce unreachable garbage objects. The algorithm can be altered in order to fight the fragmentation it naturally induces and requires a strong cooperation from the runtime system or the compiler to implement the write barriers efficiently.
Limited Memory
The heap in an embedded system can't be expanded because of the lack of virtual memory. This makes running out of memory a critical situation that applications will want to avoid using preventive measures. Since it's impossible for a Java application to explicitly free memory, it can only make its best effort to ensure that references to an object are suppressed. It can be worthwhile to encourage references to huge but easily recomputable objects using weak references. Weak references are reported to be introduced in JDK 1.2. They allow references to an object to be maintained without preventing the object from being reclaimed by the collector. Applications may also use theMemoryAdvice interface to
be implemented by the RunTime class in JDK 1.2. It
defines the getMemoryAdvice method that returns four
indicators of the memory usage, as estimated by the runtime
environment, from GREEN --- everything is fine --- to
RED --- take every conceivable action to discard objects.
In the case of an application running out of memory, an aggressive
garbage collection pass should be performed. The garbage collector
must be guaranteed the memory this operation requires. Since some
stack and some heap may be necessary, the system needs to monitor the
low-water mark, and prevent the application from totally running out
of memory before taking action. If no memory can still be found, the
system throws an OutOfMemoryError error and it's up to
the application to selectively choose which parts should be discarded.
Pluggable Garbage Collection
Being able to characterize the dynamic memory allocation behavior of an application helps in choosing a garbage collection algorithm. For example, if it appears that the embedded application is known to build no cyclic data structures, then a derived reference counting algorithm might be appropriate. If allocated objects are known to be fairly similar in sizes, then a non-compacting algorithm might be used.Instrumentation of memory allocations behavior, including peak size, object sizes, and life spans statistics will help a developer select the correct garbage collection algorithm. Such monitoring can be performed during the development and test phases by using a special version of the runtime environment. The next step is to assist the developer by allowing them to plug and tune the garbage collector of their choice.
These issues are being seriously examined at Cygnus. Being in control
of the tools that generate the code gives us opportunities to ease the
work of a garbage collector in many ways. We can precisely perform
any relevant static allocation of objects and implement write
barriers, even though the implementation of this may be challenging if
we want to support pluggable collectors. An efficient write barrier
needs to interact very closely with the collector in use, being aware
of either its internal data structures or the object marking in use.
They usually feature between ten to thirty instructions and can't
really afford the versatility of using function calls. One solution
might be to specify the write barrier as a user-editable piece of
code, which can be inserted as necessary by the compiler during the
instruction generation phase. Developing our own compiler also gives
us a chance to analyze the way finalizers are written, thus detecting
actions that resuscitate objects being thrown away. This could be
done by analyzing the use of this as an expression
right-hand side or method parameter.
Different embedded systems applications are likely to require different garbage collection algorithms. There are at least four relevant classes of embedded systems:
- Small memory systems with no real time requirements.
- E.g. 128k total ROM, 64k total RAM.
- No need for incremental GC.
- Small memory systems with real time requirements.
- E.g. 128k total ROM, 64k total RAM.
- May need incremental GC.
- Moderate/large memory systems with low object turnover.
- E.g. 512k total ROM, 512k total RAM.
- Incremental GC needed; probably mark and sweep.
- Moderate/large memory systems with high object turnover.
- E.g. 512k total ROM, 512k total RAM.
- Incremental GC needed; probably generation GC or reference counting.
A Java runtime capable of instrumenting the memory allocation patterns coupled with the possibility of a pluggable garbage collector seems the most attractive long-term option. Cygnus does not intend to develop such a system immediately, but will maintain it as a long term goal. In addition, with time and the study of the memory allocations behavior of embedded applications written in Java, we eventually hope to develop a collection of ready-to-use garbage collector algorithms that embedded system developers will be able to directly incorporate into their designs.
In addition to pluggability, tuneability will be an important requirement. Tuneability is necessary so the end developer can set the various garbage collection algorithm parameters for optimal performance.
4.0 The Java Class Libraries
The Java language packages up modules of standard functionality into standardized class libraries. Each class library contains a collection of classes and methods developers can use to help develop their applications. Originally, there was only a few class libraries. Now however, because Sun is attempting to position Java as an alternative to Microsoft Windows, the number of standardized class libraries have proliferated. Whether all the different class libraries Sun has defined will ever be widely used isn't clear. What is clear is that many of the class libraries defined for use on PCs are inappropriate for embedded systems. A much smaller set of class libraries are needed for use by embedded systems.Class libraries are being developed to support compiled Java code. No runtime support for interpreted Java language code will be provided. Third-party Java interpreters will be expected to include their own implementations of whatever class libraries they need, rather than rely on those developed by Cygnus. The reason for this is that it isn't possible to develop the lowest level class library routines without a detailed knowledge of the implementation techniques used by the underlying Java system. In the case of a third-party Java interpreter these low-level implementation techniques are unlikely to be known.
4.1 Java Class Library Overview
The most relevant class libraries defined so far are:-
java.lang- core language classes that deal with basic system types -
java.lang.reflect- introspection and reflective language features -
java.util- utility routines -
java.util.zip- utility routines for data compression -
java.io- input and output facilities providing both file and stream based I/O abstractions -
java.net- networking -
java.awt.*- Abstract Windowing Toolkit GUI windowing facilities -
java.awt.swing.*- SWING toolkit intended as a replacement for most of the original AWT facilities -
java.applet- Web browser applets -
java.security- Authentication and encryption -
java.text- Structured textual input/output for dates, currency, and so on -
java.math- Infinite precision arithmetic -
java.rmi.*- Remote method invocation -
java.sql- SQL database access -
java.beans- Component based application construction
4.2 Class Library Selection
Most of the above class libraries are not relevant to the needs of embedded systems.
A subset of java.lang, java.util, and
java.io should be more than sufficient for most embedded
applications.
For some embedded systems, some of the features of
java.lang.reflect might be useful. Initially, however,
we will likely be deferring on the implementation of these features.
In large part this is because it is difficult to provide introspective
features without substantially increasing the code size of
applications including those that don't even take advantage of these
features. At some as yet undetermined point in the future, it will
likely be necessary for Cygnus to support
java.lang.reflect, but not today.
java.util.zip is primarily of use to decode compressed
class files. The priority of this isn't clear. Currently we are not
planning to support it.
The features of java.net are useful for embedded systems
connected to the Internet. However, lacking the necessary TCP/IP
protocol stack, it would be pointless for Cygnus to attempt to
implement this module. One day in the future, Cygnus might decide to
support java.net. Exactly when will likely depend on
customer need.
What to do about graphics in embedded systems is an interesting question. Sun's original AWT graphics library has essentially been abandoned by Sun, and Sun is now attempting to replace it with SWING. Whether they will be successful isn't yet clear. Even if they are successful, it has yet to be determined whether such a large graphics library as AWT or SWING is useful in the embedded systems space. For the time being, we are deferring attempting to decide upon a Java graphics library for embedded systems.
Interestingly, java.applet is the only class library
explicitly listed as not being supported in Sun's EmbeddedJava
specification. Applets are only relevant in the web browser context.
The ability to dynamically load and execute bytecodes is not part of
the java.applet specification, but is included in the
base java.lang specification. Support for
java.applet will not be provided.
java.security is most relevant in conjunction with
java.applet. Lacking java.applet,
java.security will also not be provided.
java.text and java.math are only relevant in
very specific application circumstances, and will not be supported.
java.rmi.*, java.sql, and
java.beans are most relevant in the enterprise software
development space, and have little relevance to embedded systems.
They will not be supported.
4.3 Class and Method Selection
The full set of classes contained injava.lang,
java.util, and java.io are unlikely to be
necessary for embedded systems development. However, as a result of
the difficulty in deciding precisely which classes and methods are
necessary, Cygnus will likely implement close to the complete set of
classes contained in these libraries. Only those classes and methods
that are clearly meaningless, useless, or irrelevant in the context of
an embedded system are planned not to be implemented.
Classes not relevant to embedded systems are primarily those that deal with operating system abstractions unlikely to be available in the context of an embedded system. In particular, classes that deal with file and process abstractions are not relevant.
So far, Cygnus has identified the following classes as not relevant for embedded systems:
-
java.lang.Process -
java.lang.SecurityManager -
java.io.FileInputStream -
java.io.FileOutputStream -
java.io.RandomAccessFile -
java.io.File -
java.io.FileDescriptor -
java.io.FileNotFoundException
4.4 Library Implementation
While relatively laborious, the implementation of the class libraries should be straightforward. In some cases, the classes and methods can be implemented entirely in Java. In other cases, it will be necessary to use C or C++. The use of a common object model between C++ and Java will greatly simplify implementing classes in a language other than Java. Some low-level classes will need to be aware of details of the compiler implementation, and as such only be useable in conjunction with the Cygnus Java compiler.In developing the class libraries, significant attention will be paid to code size, as is clearly appropriate for embedded systems. Particularly important in this regard will be the class libraries associated with Unicode characters. Special procedures or limitations on these classes might be necessary to ensure the translation tables associated with these classes don't consume excessive memory, especially in applications for which the full functionality provided by these classes isn't required.
In addition to developing the class libraries, it will also be necessary to purchase or develop a relatively large test suite to test the class libraries for conformance to the relevant standards. This will be useful to identify bugs in the class libraries. Note that while generally committed to following standards, Cygnus may intentionally choose to deviate from strict class library standards conformance whenever appropriate to the development of a compiler-based embedded implementation of the Java platform. There are particular issues associated with both compiled and embedded Java that might warrant behaving differently than in the traditional interpreter based PC Java platform implementation.
5.0 User Interface Design
Graphical user interfaces are easy to use and enhance programmer productivity. Command line interfaces provide programmers with power. Command line interfaces are sometimes better suited to large scale software development projects, with their attendant complicated build requirements and procedures.Cygnus is committed to the support of both graphical and command line interfaces and seeks to put the power to choose between the two in the hands of the end developer.
The traditional GNUPro tools use a command line based interface. Cygnus Foundry is a graphical Integrated Development Environment (IDE) for use in developing embedded systems. Foundry includes:
- Source Code Editor
- Graphical Build Tool
- Graphical Debugger
A number of enhancements will need to be made to both the command line GNUPro tools and Foundry in order for them to work with Java.
5.1 GNUPro Java Enhancements
The main command line user interface changes necessary to support the Java language are additional command line options for GCC. Most of the language independent and target specific flags will work unchanged. Additional command line flags will be necessary to give embedded developers control over the way in which GCC compiles Java code, as well as options to specify the Java runtime environment.The additional command line options that may need to be added to GCC include:
- Whether to just compile a file down to bytecode or to produce machine code.
- Whether the generated code needs to work with a third-party VM.
- What stubs or other automatically generated code should be produced for providing compatibility between C++ and Java.
- Whether to adhere to the Java language specification which requires detecting array bounds violations, and performing other run time type checking, or whether to instead generate smaller, high performance code.
- Whether to generate full reflective information, or to omit as much of that as possible.
- Which debugging information to preserve at runtime.
- What type of garbage collector should be used.
- Tuning parameters associated with the chosen garbage collector.
- Code generation requirements for the use of an end-user pluggable garbage collector. This has to do with whether GCC needs to insert read and/or write barriers before accessing various objects, or to follow conventions and emit tables for use by a precise garbage collector.
5.2 Cygnus Foundry Java Enhancements
Two types of enhancements to the Foundry IDE will be necessary to allow it to be used to develop Java applications. The first type involves providing menus, dialog boxes, and other graphical interfaces to the previously listed enhanced command line functionality. The second type of enhancement involves changing and generalizing interfaces in Foundry that made sense when the only development languages available were C and C++. For instance, certain menu options currently displayed as general compiler options need to be moved into a separate menu of options that is specific to the compilation of C and C++.Additionally, it will be necessary to modify the Foundry build model so the end user can specify whether to compile down to bytecode or to machine code.
As well as the Foundry Java enhancements, it will be necessary to enhance Foundry to support the target processor. While not trivial, the nature of this work is well understood. The most significant aspect of this work will likely be the development of a board support package for Foundry enabling the debugger to communicate with the chosen target reference board.
6.0 Debugging
For industrial deployment of software technology, the ability to debug applications is vital. Support for high quality debugging tools has historically been severely neglected in the Java development community. Nowhere is this truer than in the embedded space. Cygnus is committed to the development of a high quality solution for debugging embedded Java systems. The challenges are formidable, but the needs for industrial strength debugging tools for embedded Java systems are vital.One of the most difficult aspects of debugging Java systems is a result of the interpreted nature of many Java implementations. This interpreted nature makes it difficult to use traditional debuggers interfacing with the target at the machine code level. Cygnus plans to provide support for debugging both compiled and interpreted Java. For the long term, it would be desirable to provide seamless integration between debugging compiled and interpreted Java code. For now, however, separate debuggers will be used for debugging compiled Java code, and for debugging interpreted Java code. Using separate debuggers is a result of the complexity of the work involved in attempting to integrate the two.
As part of Cygnus' plans for GDB 5, we currently intend to extend GDB to allow it to simultaneously support the debugging of multiple targets. This work will make it much easier to arrange for a single debugger to support debugging both interpreted and compiled Java.
Performance is critical to embedded systems, both in terms of memory
use and execution time. Historically Java has provided little support
for performance analysis tools. The current development plans do not
involve the creation of any special tools for Java performance.
However, the ability to use GCC to compile Java to machine code should
make it relatively easy to use or adapt existing profiling tools, such
as the gprof profiler, and the gcov coverage
analyzer, for embedded Java in the future.
6.1 The GNUPro Debugger
GDB is the GNUPro source level embedded debugger. It currently provides support for C and C++ source level debugging on a wide range of embedded targets. Features include the ability to examine registers and memory, set breakpoints, disassemble code, step through code at the source and machine code level, print out objects, and to evaluate expressions expressed in the syntax of the source language.GDBTk is a graphical user interface for GDB. GDBTk is included as part of Cygnus Foundry Integrated Development Environment. GDBTk has the same look and feel on both Windows and Unix platforms and offers the ease of a GUI with the power of GDB's command-line interface.
6.2 The JVMDI
The Java Virtual Machine Debugger Interface (JVMDI) is a published debugging interface for Java. Sun will provide support for the JVMDI starting in the forthcoming JDK 1.2 release, expected to be available in mid-1998. Sun will not continue to support the old debugging interface used in their JDK 1.1 release.The JVMDI provides a C language interface for controlling the execution of an interpreter based Java environment for debugging purposes. It provides an abstract high level representation of the state of the virtual machine. Routines are provided for accessing objects, examining the VM stack, setting breakpoints, and controlling the execution of threads. The JVMDI is primarily intended to provide the facilities necessary to allow a debugger to debug an interpreter based VM, rather than compiled Java code.
The JVMDI interface is a Java Native Interface (JNI). All JVMDI
functions are Java native methods, meaning they can be readily called
from C or C++ in addition to Java. Each function is passed a Java
thread specific JNIEnv parameter. This means that JVMDI
must be invoked by a Java thread and started by the Java application.
This debugging thread can, however, control other threads.
6.3 User Interface Issues
The extension of GDBTk to support Java will be straightforward. It should only be necessary to add a few additional menu options and dialog boxes.6.4 Debugging Compiled Java
GDB will be extended to support the debugging of compiled Java code. GDB already understands how to debug C and C++, and so adding support for Java should be relatively simple.Having a single debugger that is able to understand C, C++, and Java, should make it significantly easier to debug multi-language applications, which are likely to predominate in embedded systems.
Adding support for Java requires adding a Java expression parser, as well as routines to print values and types in Java syntax. It should be easy to modify the existing C and C++ language support routines for this. Java expressions and primitive types are fortunately fairly similar to those of C++.
When debugging C and C++, GDB is able to evaluate arbitrary user-supplied expressions, even those that include function calls. To support this in Java will mean adding support for invoking a method in the program being debugged. If a VM is present, GDB may be able to invoke a function in the VM to do this job on its behalf. Unfortunately though, we can't rely on the presence of a VM. It is thus necessary for the compiler to generate a substantial amount of symbolic debugging information for Java, similar to what is already generated for C and C++.
GDB will need to also need to include support for Java objects. The
getting, setting, and printing of object fields will be basically the
same method as that used for C++. Printing object references can be
done using a format similar to that used by the default
toString method: the class name followed by the address,
such as "java.io.DataInput@cf3408". Sometimes the user
will want to print the contents of the object, rather than its
address. Strings should, by default, be printed using their contents,
rather than their address. For other objects, GDB can invoke the
toString method to get a printable representation, and
print that. However, there will need to be different options to get
different styles of output.
GDB maintains an internal representation of the types of the variables and functions in a program being debugged. These are read from the symbol-table section of the executable file. To some extent this information duplicates metadata that may already need to be in the program's address space. We can save some file space if we avoid putting duplicate metadata in the symbol table section, and instead extend GDB so it can get the information it needs from the running process. This also makes GDB startup faster, since it makes it easier to only create type information when needed. Care has to be taken however to ensure we don't include any runtime metadata that isn't strictly necessary, since this would then serve to increase the size of the resulting application.
Potentially duplicated metadata might include source line numbers. This is because a Java program needs to be able to do a stack trace, even without an external debugger. Ideally, the stack trace should include source line numbers. Therefore, it may be best to put the line numbers in a special read-only section of the executable. This would be pointed to by the method metadata, where both GDB and the internal Java stack dump routine can get at it. For production embedded code one would leave out line numbers in the runtime, and only keep them in the debug section of the executable file.
6.5 Debugging Interpreted Java
GDB will provide support for debugging interpreted Java running on a third-party Java interpreter. This support will be provided via a JVMDI interface provided by the third-party Java interpreter. No support for debugging Java interpreters that do not support the JVMDI will be provided.The debugger for interpreted Java will be a separate application from the debugger for compiled Java. For the time being, it won't be possible to use a single debugger to debug an application containing a mixture of interpreted and compiled Java code. This also means it won't be possible for the interpreted Java debugger to debug native methods.
There are three significant areas of work associated with providing support for debugging interpreted Java:
- Interpreter support. The architecture of GDB needs to be substantially modified to make it capable of debugging interpreters. Today GDB is only capable of debugging compiled code, and all of the internal details of GDB deal with low-level concepts such as addresses, words, and registers, that are only really relevant for compiled code.
- JVMDI support. Specific support will need to be added to enable GDB to control a Java interpreter via the JVMDI interface.
- Java support. GDB needs to be extended to support the Java language. Most of this work is already necessary for GDB to be able to support compiled Java.
The target VM needs to provide the JVMDI interface. A stub routine will be written that is linked in to the target VM using the JVMDI. This stub code will be responsible for communicating with GDB via a serial line or other communication means. GDB will then instruct the stub to invoke various JVMDI functions.
Symbols
For C and C++, GDB reads the symbol table associated with an executable to obtain static information about functions, data, types, and so on. In Java, much of this information is loaded into the VM runtime along with the actual executable code and is available at runtime to applications, using various "reflective" methods. However, not all of the useful symbolic information contained in a Java class file is loaded into the VM, and some of the information that is loaded is not accessible via Java methods, the JNI, or JVMDI. Consequently GDB will need to be able to read as much symbolic information as possible from ".class" files.
The reading of symbol tables from files before an application starts also allows the setting of breakpoints before a program is loaded, and is consistent with GDB's current execution model.
In Java, each source file can define one or more classes. However,
the compiler generates a separate ".class" file for each
class. The ".class" file provides type information about
the class, which GDB can use to create the internal type information
for the class that GDB requires. The class file may also include line
number information, names and types of local variables, as well as the
actual bytecode itself.
In GDB, the symtab or psymtab structures hold symbolic information for
a particular source file. These structures are really intended to be
associated with individual source files. Thus we should read all of
the ".class" files resulting from a single source file,
and put all the information in the same symtab/psymtab.
Unfortunately, finding all the classes for a single source file is
problematic. It might be easier to create a symtab per class, rather
than a symtab per source file.
Where to Find Initial Symbols
GDB allows browsing of symbol information, source, and assembly code before an executable has been started. However, this does not work for shared libraries until they have been loaded. Java is like an extreme shared library environment in that all code is dynamically loaded --- at least in Sun's model --- and new classes can be created from out of nowhere.An important simplification, though, is that there is only one kind of global symbol: the class name. To set a breakpoint on a named method, the user has to name the class. Thus GDB can use the same search path used by the runtime to find the actual class files, and read symbols from it. This assumes the same classes are available to GDB as to the JVM, which may require some coordination in the case of embedded systems.
Java can create new classes from a byte array, using a ClassLoader mechanism. This is used to read applets over the network. GDB will not be able to find such classes, but since they do not have global names, nor can they be created until after the VM has started up, this is acceptable.
Java does not mesh well with GDB's current symbol handling. GDB
assumes that all allowable global symbols have been read. For Java,
though, we will not read symbols on startup. We will thus need to
craft a hook inside the Java VM target that can be invoked by GDB's
lookup_symbol routine whenever a symbol is not found.
Naming source files, perhaps by setting a breakpoint on a line in a file, is also difficult, at least for classes whose symbols have not yet been read. We can handle most cases using the standard direct mapping between Java source file names and Java classes. We would map the source file name into the expected Java class name, and try to load it. However, we will also need a fallback approach when this does not work.
Partial Symbols
In the previous section, it was explained that Java has much less need of partial symbol tables than what GDB offers. However, we do occasionally need to actually go and read all the classes in the CLASSPATH, and use that to build psymtabs. Examples might include various info commands, or when the user names a source line that is in a class whose name does not match its source file name.
Unfortunately, finding all the possible valid classes is an expensive
task. The CLASSPATH can name either zip archives or directories. Zip
archives are easy to scan. Scanning a directory though means
searching for all the ".class" files in that directory
and its sub-directories. Whether, and when, to go this far should
probably be under user control, depending on settable preferences or
explicit request.
Once we have found a ".class" file or archive member, we
need to save the class name and the name of the source file. The
source file name is specified in a SourceFile attribute,
which is at the end of the ".class" file. The
SourceFile attribute is not supposed to specify a source
directory. Instead, this has to be inferred from the package name
prefix of the class name.
Addresses
GDB's model of a target is a linear address space, plus a set of per-thread registers. Addresses are a fairly fundamental concept in GDB. We need to map the Java VM into this linear address space, consisting of "text," "data" and "stack".A normal address space has three parts:
- Text. This is where bytecode instructions logically belong.
- Static data. This is where Java objects are. It may also be where the class objects and constant pool are.
- Stack. This is where the Java method frames live.
Code Addresses
GDB assumes there are instructions in text memory. It assumes there are a number of functions; all instructions belong to a function; the instructions of a function form a continuous sub-range of text; and each instruction has an integer address associated with it. This address is used for setting breakpoints, disassembling, finding sources lines, and identifying the current PC location.
Most of these assumptions can be met in Java. The main problem is
associating a unique integer address with each instruction. To do
this, we basically have to fake up addresses. We do associate a
method number with each method that GDB cares about, and then
concatenate that with the code offset within a method. For example,
if the method java.lang.StringBuffer.toString has method
number 0xA79, then the instruction at the 5th byte of that method will
have address 0xA790005. (The Java VM specification limits Java
methods to 2^16 bytes.) Note that the address of a method would be
the address of its first instruction; 0xA790000 in the above example.
This leaves the question of how to assign a method number to a method. These numbers are arbitrary. All that matters is that we can consistently translate between the number GDB uses, and whatever MethodIDs are used by the JVM stub. It might make sense to allocate them such that all method numbers for method in a given class are continuous.
Breakpoints
The JVMDI has functions to set and clear breakpoints, given a method and bytecode index. So, given a mapping between methods and method numbers, setting a breakpoint at a known instruction is easy.Disassembly
In GDB, disassembling an instruction is an operation that takes an address, interprets it as the location of an instruction, prints that instruction in human-readable format, and then returns the address of the next instruction. As long as we have a mapping between instruction locations and numerical addresses, we can readily do this for Java bytecodes. The only complication is that the JVMDI provides no access to the actual bytecodes of the method. Instead we have to obtain this information from the class file. Hence, either GDB or the GDB stub in the VM needs to find the class file that the method was loaded from, and use this information for the disassembly.
Finding the correct class file involves searching the CLASSPATH. This
will not work for classes loaded/created dynamically using a
ClassLoader, unless we can set a breakpoint on the ClassLoader's
defineClass method. This may or may not be worth the
effort.
Frames and Local Variables
For stack traces, GDB assumes each frame has an address. For accessing local variables, GDB assumes each non-register local variable and parameter also has an address inside this frame.
Each local variable in the JVM, and in the JVMDI, has a frame slot
index, and takes one or two frame slots. A slot must be big enough
for a pointer. If we use 32-bits pointers, it makes sense to
associate the slot numbered i with the GDB frame offset
4*i. The slot numbers are obtained from the
LocalVariableTable attribute when we read the
".class" file containing the method of the frame.
GDB needs an address for each frame. We can use something similar to
(THREAD#<<24)|(FRAME#<<18)), where the
address of a local variables is
(THREAD#<<24)|(FRAME#<<18)|(SLOT#<<2).
The FRAME# is 0 for the top-most frame, 1 for its caller,
etc. The JVMDI stub can get the correct jframeID by
calling JVMDI_GetCallerFrame FRAME# times.
Static Fields
The JVMDI stub can access static fields using the JNI. However, GDB still needs a pseudo-address for each static field. These can again be generated arbitrarily since the stub never needs these addresses. For example,(CLASS#<<18|INDEX<<2) can be
used to access the INDEXth static field of the class.
Values
Java has primitive values such asint and
float, and also reference values. The primitive values
are easy to handle. The reference values are conceptually pointers to
objects and are more complex to handle in the debugger.
Garbage collection is one complication. If we print out a pointer,
and save it in a GDB convenience variable, when we continue it is
possible that garbage collection has removed the object by the next
time we stop. Conceptually, we have a similar problem with
malloc()/free() in C. However, many more
objects are heap-allocated in Java, and their lifetimes are less
controllable. Worse, it is possible that an object might still be
live, but a copying collector has moved it somewhere else. In other
words, we cannot rely on machine addresses to represent pointers.
JNI provides a way to make a reference "global." Making a reference global locks it down, and prevents the GC from moving it. Unfortunately, it also prevents the GC from freeing it, which means we may be changing the behavior and memory usage of the application in ways we don't want.
JDK 1.2 (beta) has what it terms "weak references." These may provide a solution. Basically weak references are objects that can point to other objects, but do not prevent the pointed to objects from being collected, in which case the reference is changed to null. Thus for each reference value that is returned to GDB, the stub creates a weak reference, generates a unique address for the reference, and returns that address. When GDB needs to get the fields of the referenced object, the stub first checks to see if the objects has been reclaimed, in which case the weak reference contains a null pointer. If so, GDB prints an error. Otherwise, the stub returns the current value of the object objects indirectly referenced by the weak reference.
Using abstract generated addresses to refer to objects instead of
hardware addresses provides us with target independence. It is
desirable to have a single jvm target to configure GDB
rather than jvm-embedded-target1,
jvm-embedded-target2, jvm-solaris2, and so
on. To do this, we have to use a standard pointer size. That means
if we used hardware addresses to encode Java references, we would have
select a pointer size large enough for all targets, such as 64 bits.
But if we instead use abstract addresses, we can get by with more
convenient 32-bit references.
Events
The JVMDI has a callback model, where various events such as hitting a breakpoint call a previously registered handler. When the handler is called, it will need to figure out what happened, and send appropriate data to GDB.Line Numbers
Line numbers are not available via the JVMDI, and need to be read from a method's class file. Once we have a method number and the corresponding method name, and we have located the correct class file, reading the line numbers is straightforward. Reading the line numbers should be conceptually similar to reading this same information for debug formats. No other changes to GDB should be necessary to support line numbers. We can use the existing GDB data structures and code.Execution
The JVMDI uses a separate debugger thread. This would be the stub that communicates with GDB.Normally, a Java application is executed by typing:
java ClassName arguments ...
When debugging, the debugger thread needs to be in control; however,
we want to hide this from the user. We don't want the user to have to
manually start up the debugger thread. Instead, we will create a
debugger stub class:
package cygnus.gdb;
public class Stub {
public static main(String[] args)
{
initialize debugger thread and setup connection with GDB;
set initial breakpoints;
invoke the main method of the class named by args[0],
and passing in any remaining args;
}
}
Then when the user says:
(gdb) run ClassName arguments ...
GDB will invoke the java interpreter with the arguments as:
java cygnus.gdb.Stub ClassName arguments ...
This will cause the debugging thread to gain control of the
application.
7.0 Compatibility Issues
When developing software, we want the ability to select the most appropriate language for the needs of the problem being solved. There will always be cases where one language is more appropriate than another. C, for instance, is solid in the arena of low-level programming. Sometimes even C, though, is not low-level enough, and so we need to escape into assembly language. The introduction of Java doesn't change this.Some code might need to be written in a lower-level language for efficiency. Other code may need to be written in a lower-level language to access low-level facilities not accessible in Java. Code reuse, and the desire to use existing code bases adds a third reason for designing compatibility and interoperability into an overall system.
To deal with this need, the Java language allows Java methods to be specified as "native." This means that the method has no method body in the Java source code. Instead, there is a special flag that tells the Java virtual machine to look for the method using some unspecified lookup mechanism.
When examining the issue of compatibility between different languages, and different language implementations, there is a range of different levels of compatibility that could be implied. It pays to use some degree of precision in the terminology employed:
- Incompatible: The two systems cease to work correctly when combined.
- Coexistence: The lowest functioning level of compatibility possible. It simply means that the individual operations of the two systems do not interfere with each other.
- Interaction: Not only do the two systems coexist, but it is also possible for them to interact with each other. Such interaction might however require the use of special interfaces of coding styles.
- Interoperability: The highest level of compatibility possible. The two systems interact in an essentially natural and transparent way. The objects and constructs of one system are accessible as native objects and constructs in the other system. There isn't a need to use special interfaces or coding styles to interact with the other system.
Most of Cygnus' Java development effort is focussed on enabling coexistence and the creation of interfaces to enable interaction between systems. We do not presently attempt to solve the harder problem of interoperability. We envision systems that might be constructed from up to three separate components:
- Compiled Java. Compiled using the GNUPro compiler.
- Compiled C/C++. Compiled using the GNUPro compiler.
- Interpreted Java. Running on a third-party VM, such as Sun's JVM.
- C/C++ and Interpreted Java
- C/C++ and Compiled Java
- Interpreted Java and Compiled Java
7.1 The Java Native Interface
Sun's original Java Development Kit, JDK 1.0, defined a programming interface for writing native methods in C. This provided rather direct and efficient access to the underlying VM, but was not officially documented, and was tied to specifics of the VM implementation. There was little attempt to make it an abstract API that could work with any VM.In JDK 1.1, Sun defined the Java Native Interface (JNI), which is intended as a portable programming interface for writing native methods in C or C++. The JNI is a binary interface, allowing someone to ship a compiled library of JNI-compiled native code, and have it work with any VM implementation that supports the JNI on a particular platform.
The advantage of the JNI is its portability. The down side is that it is a rather heavyweight interface, with substantial overhead. For example, if native code needs to access a field in an object, it needs to make two function calls. Admittedly, the result of the first could be saved for future accesses. It is still cumbersome to write, and slow at runtime. Worse, for some applications, the field to be accessed has to be specified as a runtime string, and found by searching runtime reflective data structures. Thus, the JNI requires the availability at runtime of complete reflective data --- the names, types, and positions of all fields, methods, and classes. The reflective data has other uses, and there is a standard set of Java classes for accessing the reflective data, but when memory is tight, it is a luxury many applications do not need. This is especially true in the case of embedded systems.
As an example of the JNI, here is a simple Java class that might be intended for accessing a hardware timer.
package timing;
class Timer {
private long last_time;
private String last_comment;
/** Return time in milliseconds since last call,
* and set last_comment. */
native long sinceLast(String comment);
}
This class contains a single method, sinceLast(). This
method has been declared native. Here is how we would write the code
for this native method in C++ using the JNI:
extern "C" /* specify the C calling convention */
jdouble Java_Timer_sinceLast (
JNIEnv *env, /* interface pointer */
jobject obj, /* "this" pointer */
jstring comment) /* argument #1 */
{
// Note that the results of the first three statements could be saved
// for future use (though the results have to be made "global" first).
jclass cls = env->FindClass("timing.Timer");
jfieldId last_time_id = env->GetFieldID(cls, "last_time", "J");
jfieldId last_comment_id = env->GetFieldID(cls, "last_comment",
"Ljava_lang_String;");
jlong old_last_time = env->GetLongField(obj, last_time_id);
jlong new_last_time = calculate_new_time();
env->SetLongField(obj, last_time_id, new_last_time);
env->SetObjectField(obj, last_comment_id, comment);
return new_last_time - old_last_time;
}
Note both how complex it is to code even a simple task using the JNI,
and the amount of runtime overhead that is involved in accessing Java
objects through the JNI. Also note the env parameter to
the function, representing a pointer to a thread-specific area which
includes a pointer to a table of functions. The entire JNI is defined
in terms of these functions. As a result, the invocation of these
functions cannot be inlined within the code for the
sinceLast() method; that would make JNI methods no longer
binary compatible across VMs.
The JNI has a definite advantage in terms of portability, but it also has a significant price.
7.2 C/C++ and Interpreted Java
To provide compatibility between C/C++ and Interpreted Java should be relatively simple. It is assumed that any third-party Java interpreter provides supports the JNI. Consequently, all that is required is to ensure that the C/C++ code produced by the compiler is compatible with the requirements of the JNI.
The requirements of the JNI are minimal in this respect. Most of the
effort involved is simply associated with checking for any possible
unexpected problems related to known tricky areas and the compilers
code generation processes relating to setjmp()/longjmp(),
signal and exception handling, object initialization, and object
finalization.
7.3 C/C++ and Compiled Java
To provide compatibility between C/C++ and compiled Java, two possibilities have been explored, but we have yet to make a final decision. The first possibility is to simply create an implementation of the JNI for accessing compiled Java from C/C++. This has the advantage of portability. Accessing compiled Java is, however, sub-optimal in the sense that the JNI was designed for interfacing to interpreter based language implementations, and in addition the JNI imposes substantial runtime space and performance costs. Consequently, an alternative possibility is to design a much higher performance, much more straightforward interface between C/C++ and Java that can take advantage of the both languages being compiled, and moreover both languages having been compiled by the GNUPro compiler.We are presently leaning towards just providing a JNI-based interface in the short term, but wish to consider the possibility of also providing a non-JNI-based interface in the future.
Use of JNI-based Interface
Producing a JNI-based interface between C/C++ and compiled Java should be relatively straightforward, although it involves a considerable amount of work. It entails both creating a complete implementation of the very large number of JNI routines, and ensuring that the compiler generates and preserves all the information necessary to do things such as dynamically look up fields at runtime as required by the JNI. Equally important is ensuring the compiler discards such information when it determines this information isn't going to be needed at runtime. Without this capability, use of a JNI-based interface would involve a substantial memory overhead.Additional work is required to ensure that the JNI for the compiler can co-exist with any JNI provided by a third-party Java implementation. This work is described later.
Application level use of a JNI-based interface is relatively well understood. It is quite feasible, albeit clumsy and inefficient.
Use of a Non-JNI-based Interface
We are presently intending to provide a JNI-based interface between C/C++ and Java. We also consider the possibility of a non-JNI-based interface, both to estimate its feasibility, and so we can design other components of the system in such a way as not to preclude it as a future option.The advantages of a non-JNI-based interface between C/C++ and Java are the interface can be more memory efficient, offer higher performance, offer a more natural programming API, and provide easier access to low level features. The basic idea is to make use of the Java language compatible with the GNUPro C++ implementation, provide hooks in GNUPro C++ so C++ code can access Java objects as naturally as native C++ objects.
We will go into more detail about the Cygnus Native Interface/Compiler
Native Interface (CNI) below. However, the key is that the calling
conventions and data accesses for CNI are the same as in normal
natural code. Thus there is no extra JNIEnv parameter,
and the C++ programmer gets direct access to the VM representation.
This interoperability requires coordination between the C++ and Java
implementations.
A possible disadvantage of the interface proposed here is it might only simplify interfacing C++ and Java, while doing little to help interface C and Java.
Here is the earlier example written using CNI:
#include "timing_Timer.h"
timing::Timer::sinceLast(jstring comment)
{
jlong old_last_time = this->last_time_id;
jlong new_last_time = calculate_new_time();
this->last_time_id = new_last_time;
this->last_comment_id = comment;
return new_last_time - old_last_time;
}
The above code uses the following automatically-generated
timing_Timer.h file:
#include <CNI.h> // "Cygnus Native Interface"
class timing {
class Timer : public java::lang::Object {
jlong last_time;
jstring last_comment;
public:
jlong virtual sinceLast(jstring comment);
};
};
This code is generated automatically by the compiler from the
corresponding Java source.
API and Programming Issues
Using the C Language
Some programmers might prefer to write Java native methods using C. The main advantages of C are that it is both more universally available and more portable. However, if portability to multiple Java implementations is important, one should use the JNI. Still, it might be nice to haveJv-style macros that would allow one to
select between portable JNI-based C, or the optimize CNI. The problem
is that an efficient CNI-style interface is much more inconvenient in
C than in C++. For the latter, we have the compiler to handle
inheritance, exception handling, name mangling of methods, and so on.
In C the programmer would have to do much more of this work by hand.
It should be feasible to come up with a set of macros for programmers
willing to do that, although this is not a high priority.
A simpler solution might be for C programs to write C-like code, but to simply compile this code using a C++ compiler.
Utility Macros
Whether or not we use the JNI, we still need a toolkit of utility
functions so C++ code can request various services of the VM. For
operations that have a direct correspondence in C++ (such as accessing
an instance field or throwing an exception), we want to use the C++
facility. For other features, such as creating a Java string from a
null-terminated C string, we need utility functions. In such cases we
define a set of interfaces that have similar names and functionality
as the JNI functions, except they do not depend on a
JNIEnv pointer.
For example, the JNI interface to produce a Java string from a C string is the following in C:
jstring str = (*env)->NewStringUTF(env, "Hello");
and the following in C++:
jstring str = env->NewStringUTF("Hello");
The C++ interface is just a set of inline methods that mimic the C
interface. In the CNI, we do not use a JNIEnv pointer,
so the usage would be:
jstring str = JvNewStringUTF("Hello");
We use the prefix Jv to indicate the CNI facilities.
It is useful to be able to conditionally compile the same source to
use either the fast CNI or the portable JNI. This can be achieved
with only some minor inconveniences. When USE_JNI is
defined, the Jv features can be defined as macros that
expand to JNI functions:
#if USE_JNI
#define JNIENV() JvEnv /* Must be available in scope. */
#define JvNewStringUTF(BYTES) ((JNIENV())->NewStringUTF(BYTES))
#else
extern "C" jstring JvNewStringUTF (const char*);
#endif
Field access is trickier. When using JNI, we have to use a
jfieldId, but when using CNI we can access the field
directly. We require that the programmer use a convention where the
jfieldId used to access a field named foo is
foo_id.
#if USE_JNI
#define JvGetLongField(OBJ, FIELD) (JNIENV()->GetLongField(OBJ, FIELD##_id))
#else
#define JvGetLongField(OBJ, FIELD) ((OBJ)->FIELD)
#endif
We might write the earlier example to support either interface by doing:
#if USE_JNI
extern "C" jdouble
Java_Timer_sinceLast (JNIEnv *JvEnv, jobject JvThis, jstring comment)
#else
jdouble
timing::Timer::sinceLast(jstring comment)
#endif
{
#if USE_JNI
jclass cls = env->FindClass("timing.Timer");
jfieldId last_time_id = env->GetFieldID(cls, "last_time", "J");
jfieldId last_comment_id = env->GetFieldID(cls, "last_comment",
"Ljava_lang_String;");
#endif
jlong old_last_time = JvGetLongField(JvThis, last_time);
jlong new_last_time = calculate_new_time();
JvSetLongField(JvThis, last_time, new_last_time);
JvSetObjectField(JvThis, last_comment, comment);
return new_last_time - old_last_time;
}
Packages
The only global names in Java are class names and packages. A package can contain zero or more classes, and also zero or more sub-packages. Every class belongs to either an unnamed package or a package that has a hierarchical and a globally unique name.
A Java package needs to be mapped to a C++ namespace. The Java class
java.lang.String is in the package
java.lang, which is a sub-package of java.
The C++ equivalent is the class java::lang::String, which
is in the namespace java::lang, which is in the namespace
java.
The automatically generated C++ code for this might be as follows:
// Declare the class(es), possibly in a header file:
namespace java {
namespace lang {
class Object;
class String;
}
}
class java::lang::String : public java::lang::Object
{
...
};
Having to always use the fully qualified class name is verbose. It
also makes it more difficult to change the package containing a class.
The Java package declaration specifies any following
class declarations are in the named package, without the need for full
package qualifiers. The package declaration can be
followed by zero or more import declarations, which
allows either a single class or all the classes in a package to be
named by simple identifiers. C++ provides something similar with the
using declaration and directive.
The simple Java import declaration:
import PackageName.TypeName;
allows the use of TypeName as shorthand for
PackageName.TypeName. The equivalent C++ code is:
using PackageName::TypeName;
A Java import on demand declaration:
import PackageName.*;
allows the use of TypeName as shorthand for
PackageName.TypeName The equivalent C++ code is:
using namespace PackageName;
Synchronization
Each Java object has an implicit monitor. The Java VM uses the instructionmonitorenter to acquire and lock a monitor,
and monitorexit to release it. The JNI has corresponding
methods MonitorEnter and MonitorExit. The
corresponding CNI macros are JvMonitorEnter and
JvMonitorExit.
The Java source language does not provide direct access to these
primitives. Instead, there is a synchonized statement
that does an implicit monitorenter before entry to the
block, and does a monitorexit on exit from the block.
Note that the lock has to be released even if the block is abnormally
terminated by an exception, which means there is an implicit
try-finally.
From C++, it makes sense to use a destructor to release a lock. CNI defines the following utility class:
class JvSynchronize() {
jobject obj;
JvSynchronize(jobject o) { obj = o; JvMonitorEnter(o); }
~JvSynchronize() { JvMonitorExit(obj); }
};
The equivalent of Java's:
synchronized (OBJ) { CODE; }
can be simply expressed in C++ as:
{ JvSynchronize dummy(OBJ); CODE; }
Java also has methods with the synchronized attribute.
This is equivalent to wrapping the entire method body in a
synchronized statement. Alternatively, the
synchronization can be done by the caller wrapping the method call in
a synchronized. That implementation is not practical for
virtual method calls in compiled code, since it would require the
caller to check at runtime for the synchronized
attribute. Hence our implementation will have the called method do
the synchronization inline.
Exceptions
It is a goal of the design of the GCC exception handling mechanism that it be as language independent as possible. The existing support is geared towards C++, but should be extended for Java. Essentially, the Java features are a subset of the GNUPro C++ features, in that C++ allows near-arbitrary values to be thrown, while Java only allows the throwing of references to objects that inherit fromjava.lang.Throwable. Cygnus is currently working on
making GCC exception handling more robust, more efficient, and less
C++-oriented, with a specific goal of supporting Java exceptions in
jc1. The main change needed for Java is how type-matching is done.
Fixing that would benefit C++ as well. The other main issue is that
we need to use a common representation of exception ranges.
C++ code that needs to throw a Java exception should be able to use
the C++ throw statement. For example:
throw new java::io::IOException(JvNewStringUTF("I/O Error!"));
There is also no difference between catching an exception in Java and catching one in C++. The following Java fragment:
try {
do_stuff();
} catch (java.IOException ex) {
System.out.io.println("caught I/O Error");
} finally {
cleanup();
}
could equally well be expressed this way in GNUPro C++:
try {
try {
do_stuff();
} catch (java::io::IOException ex) {
printf("caught I/O Error\n;");
}
catch (...) {
cleanup();
throw; // re-throws exception
}
Note that in C++ we need to use two nested try
statements.
Object Model
From a language implementation perspective it is convenient to view Java as a subset of C++.Java is a hybrid object-oriented language, with a few native types in addition to class types. It is class-based, where a class may have static as well as per-object fields, and static as well as instance methods. Non-static methods may be virtual, and may be overloaded. Overloading in resolved at compile time by matching the actual argument types against the parameter types. Virtual methods are implemented using indirect calls through a dispatch or virtual function table. Objects are allocated on the heap, and initialized using a constructor method. Classes are organized in a package hierarchy.
All of the listed attributes are also true of C++, though C++ has extra features. For example, in C++ objects may also be allocated statically or in a local stack frame in addition to the heap. Java also has a few important extensions, plus a powerful standard class library, but on the whole this does not change the basic similarities.
Thus, the main task in integrating Java and C++ is simply to remove gratuitous incompatibilities. Below we define a common object model for Java and C++. By adhering to this model in both C++ and Java code it becomes possible for the two languages to interoperate.
Object References
In our compiled Java implementation an object reference is implemented as a pointer to the start of the referenced object. This maps to a C++ pointer. We cannot use C++ references for Java references, since once a C++ reference has been initialized, you cannot change it to point to another object. Thenull Java reference maps to
the NULL C++ pointer.
Note that in Sun's JDK, an object reference is implemented as a pointed to a two-word "handle." One word of the handle points to the fields of the object, while the other points to a method table. We avoid this extra indirection.
Primitive Types
Java provides 8 "primitives" types:byte,
short, int, long,
float, double, char, and
boolean. These correspond to the following C++
typedefs defined in a standard header file:
jbyte, jshort, jint,
jlong, jfloat, jdouble,
jchar, and jboolean.
| Java type | C/C++ typename | Description |
|---|---|---|
| byte | jbyte | 8-bit signed integer |
| short | jshort | 16-bit signed integer |
| int | jint | 32-bit signed integer |
| long | jlong | 64-bit signed integer |
| float | jfloat | 32-bit IEEE floating-point number |
| double | jdouble | 64-bit IEEE floating-point number |
| char | jchar | 16-bit Unicode character |
| boolean | jboolean | logical (Boolean) values |
| void | void | no value |
Object Fields
Each object contains an object header, followed by the instance fields of the class, in order. The object header consists of a single pointer to a dispatch or virtual function table. There may also be extra fields "in front of" the object (e.g. for memory management), but this is invisible to the application and the reference to the object points to the dispatch table pointer.
The fields are laid out in the same order, alignment, and size as
occurs today for C++. Specifically, 8-bit and 16-bit native types
(byte, short, char, and
boolean) are not widened to 32 bits. Note that the Java
VM does extend 8-bit and 16-bit types to 32 bits when on the VM stack
or temporary registers. The JDK implementation also extends 8-bit and
16-bit object fields to use a full 32 bits. In the compiler however,
8-bit and 16-bit fields only require 8 or 16 bits of an object. In
general Java field sizes and alignment are the same as C and C++.
Arrays
While in many ways Java is similar to C and C++, it is quite different in its treatment of arrays. C arrays are based on the idea of pointer arithmetic, which would be incompatible with Java's security requirements. Java arrays are true objects. Array types inherit fromjava.lang.Object. An array-valued variable is one that
contains a reference (pointer) to an array object.
Arrays in Java are quite different from arrays in C++.
Referencing a Java array in C++ code needs to be done using the
JArray template, which is defined as follows:
class __JArray : public java::lang::Object
{
public:
int length;
};
template<class T>
class JArray : public __JArray
{
T data[0];
public:
T& operator[](jint i) { return data[i]; }
};
The following convenience typedefs, which match the JNI,
can also be provided:
typedef __JArray *jarray;
typedef JArray<jobject> *jobjectArray;
typedef JArray<jboolean> *jbooleanArray;
typedef JArray<jbyte> *jbyteArray;
typedef JArray<jchar> *jcharArray;
typedef JArray<jshort> *jshortArray;
typedef JArray<jint> *jintArray;
typedef JArray<jlong> *jlongArray;
typedef JArray<jfloat> *jfloatArray;
typedef JArray<jdouble> *jdoubleArray;
Implementation Issues
Overloading
Both Java and C++ provide method overloading, where multiple methods in a class have the same name, and the correct one is chosen at compile time depending on the argument types. The rules for choosing the correct method are more complicated in C++ than in Java, but the fundamental idea is the same. It is thus necessary to ensure all thetypedefs for Java types map to distinct C++ types.
Common assemblers and linkers are not aware of C++ overloading, and so the standard implementation strategy is to encode the parameter types of a method into its symbol name. This encoding is called mangling, and the encoded name is the mangled name. The same mechanism is used to implement Java overloading. For C++/Java interoperability, it is important to use the same encoding scheme.
Virtual Method Calls
Virtual method dispatch is handled essentially the same in C++ and Java --- an indirect call through a function pointer stored in a per-class virtual function table. C++ is more complicated because it has to support multiple inheritance. Traditionally, this is implemented by putting an extra delta integer offset in each entry in the virtual function table. This is not needed for Java, which only needs a single function pointer in each entry of the virtual function table. There is a more modern C++ implementation technique, which uses thunks, doing away with the need for the delta fields in the virtual function tables. This is now an option in GNUPro C++. We need to make sure that Java classes that inherit fromjava.lang.Object are implemented as if using thunks. No
actual thunks are needed for Java classes, since Java does not have
multiple inheritance.
The first one or two elements of the virtual function table need to be used for special purposes in both Java and C++. In Java they point to the class that owns the virtual function table. In C++ they point to a C++ runtime type information descriptor. The compiler needs to know that the two languages use of these elements is slightly different.
Allocation
New Java objects are allocated using a class instance creation expression:
new Type ( arguments )
The same syntax is used in C++. The main difference is that C++
objects have to be explicitly deleted, while in Java they are
automatically deleted by the garbage collector. For it to be possible
to create a Java object from within C++, for a special class we can
define operator new:
class CLASS {
void* operator new (size_t size) { return soft_new(MAGIC); }
}
However, we don't want a user to have to define this magic
operator new for each class. This needs to be done in
java.lang.Object. This is not possible without some
compiler support (because the MAGIC argument is
class-dependent). Implementing such support is straightforward.
Allocating an array is a special case that also needs to be handled,
since the space needed depends on the runtime length given.
Object Construction
In both C++ and Java, a constructor allocates newly created objects. In both languages, a constructor is a method that is automatically called. Java has some restrictions on how constructors are called, but basically the calling convention and the scheme for method overload resolution are the same as for standard methods. In GNUPro C++, methods get passed an extra magic argument, which is not passed for Java constructors. GNUPro C++ also has the constructors set up thevtable pointers. In Java, the object allocator sets
up the vtable pointer, and the constructor does not
change the vtable pointer. Hence, the GNUPro C++
compiler needs to know about these differences.
Object Finalization
A Java methods with the special namefinalize serves some
of the function as a C++ destructor method. The latter is responsible
for freeing up resources owned by the object before it is destroyed,
including deleting sub-objects it points. In Java, the garbage
collector takes care of deleting no-longer-needed sub-objects, so
there is much less need for finalization, but it is still occasionally
needed.
It might make sense to consider the C++ syntax for a finalizer:
~ClassName as being equivalent to the Java
finalize method. That would mean that if class that
inherits from java.lang.Object defined a C++-style
destructor, it would be equivalent to defining a finalize
method. Alternatively, if you want to define or invoke a Java
finalizer from C++ code, you could define or invoke a method named
finalize.
In this proposed hybrid C++/Java environment, there is no clear
distinction between C++ and Java objects. Java objects inherit from
java.lang.Object, and are garbage collected. On the
other hand, regular C++ objects are not garbage collected, but must be
explicitly deleted. It may be useful to support C++ objects that do
not inherit from java.lang.Object but that are garbage
collected. CNI may provide a way to do that, by overloading
operator new.
What happens if you explicitly delete an object in either
Java or C++ that is garbage collected? The Ellis/Detlefs garbage
collection proposal for C++ says that should cause the finalizer to be
run, but otherwise whether the object memory is freed is
unpredictable; this seems reasonable.
Interfaces
A Java class can implement zero or more interfaces in addition to inheriting from a single base class. An interface is a collection of constants and method specifications, similar to the signatures available as a GNUPro C++ extension. An interface provides a subset of the functionality of C++ abstract virtual base classes, but is normally implemented differently. The most appropriate mechanism for implementing interfaces has yet to be determined.Improved String Implementation
The standard Java implementation is a bit inefficient, because every string requires two objects. Thejava.lang.String object
contains a reference to an internal char array, which
contains the actual character data. If we allow the actual
java.lang.String object to have a size, it can vary
depending on how many characters it contains --- just like array
objects vary in size --- we can save the overhead of the extra object.
This would save space, reduce cache misses, and reduce garbage
collection overhead.
For instance:
class java::lang::String : public java::lang::Object
{
jint length; /* In characters. */
jint offset; /* In bytes, from start of base. */
Object *base; /* Either this or another String or a char array. */
private:
jchar& operator[](jint i) { return ((jchar*)((char*)base+offset))[i]; }
public:
jchar charAt(jint i)
{
if ((unsigned32) i >= length)
throw new IndexOutOfBoundsException(i);
return (*this)[i];
}
String* substring (jint beginIndex, jint endIndex)
{
/* should check for errors ... */
String *s = new String();
s.base = base;
s.length = endIndex - beginIndex;
s.offset = (char*) &base[beginIndex] - (char*) base;
return s;
}
...
}
The tricky part about variable-sized objects is that we can no longer cleanly separate object allocation from object construction, since the size of the object to be allocated depends on the arguments given to the constructor. We can deal with this fairly easily from C++ or when compiling Java source code. It is more complicated, though still quite doable, when compiling from Java bytecode. We don't have to worry about that, since in any case we have to support the less efficient scheme with separate allocation and construction, which is needed for JNI and reflection compatibility.
Changes Needed to GNUPro C++
The following changes are needed to GNUPro C++ before it can provide the C++ and Java interoperability we have discussed:- We need a utility to translate Java class definitions into
equivalent C++ class declarations. Most convenient would be adding
the ability for GNUPro C++ to directly read class properties from a
"
.class" file. However, a simple program that reads a ".class" and generates a suitable C++ include file is almost as convenient. - We need a way to indicate to GNUPro C++ that the class
java.lang.Objectis magic, in that it, and all classes that inherit from it, should be implemented following Java conventions instead of C++ conventions. We say that such classes have the "Java property." Our goal is that, on the whole, it should not matter, but there are a few places, listed above, where it does matter. - Virtual function tables and calls in classes that have the Java property are different.
- A
newexpression needs to be modified to call the correct function for classes that have the Java property. - The interface to constructors needs to be changed so magic vtable pointer initialization and the extra constructor argument do not happen when constructing a Java object.
- The
typedefs for the primitive types, such asjlong, need to map to concrete implementation types. GNUPro C++ needs some minor changes so that the mangling of those implementation types are all disjoint, and preferably that the same on all platforms. - Change representation of exception ranges to be more suitable for Java.
7.4 Interpreted Java and Compiled Java
Several options exist for providing compatibility between interpreted and compiled Java.From the end user's perspective, the ideal option would be seamless interoperability between interpreted and compiled Java, such that the end user doesn't need to know which code was interpreted and which code was compiled.
Unfortunately, the best way for compiled code to interoperate with interpreted code is for the compiled code to know all the details of the internal structures of the interpreted code. This allows the compiler to generate code and data structures that are compatible with the interpreted code, and also interpret the interpreted code's data structures itself. The necessary details include data formats, object layouts, exception handling procedures, introspective data structures, access protocols, and so on. For third-party virtual machines, a lot of this information is typically proprietary, and may also vary from one release to another, or even from one platform to another. In addition, the interpreter may need to have special hooks inserted into it to enable it to interoperate with compiled code. Frequently, it may not be possible to modify the interpreter. The interpreter may not even be provided in source code form. Consequently, this option, which would be ideal, isn't practical.
A more realistic option is, instead of providing interoperability, to simply provide a set of interfaces that a software developer can use to allow interpreted and compiled Java code to interact with each other.
There are at least three public interfaces that enable some form of access to the details of a third-party Java virtual machine, and could potentially be used to enable compiled code to interact with a third party VM. These interfaces are:
- the Java Native Interface (JNI)
- the Java object serialization interfaces
- the Java Remote Method Invocation interface
There are some complications in doing this. First, the JNI is really designed to allow a VM to interact with C or C++ code, not a different Java implementation. Consequently the JNI is designed around mapping Java concepts onto the equivalent C and C++ concepts, rather than providing a more straightforward isomorphic mapping onto Java. Second, the JNI is exposed today to the user at the language level as a C/C++ programming interface. To be able to access the JNI associated with a third-party VM will involve wrapping the standard C/C++ JNI it provides with a set of compiled Java methods so that it can be accessed by compiled Java code. These methods will have to have some differences from the corresponding C/C++ methods and routines to account for the more limited nature of the Java language, and to also make the programming experience seem more natural than it otherwise might.
The interface between compiled and interpreted Java will thus be heavyweight, and somewhat ungainly, but given the lack of access to the internals of a third-party VM, this is the best that can be reasonably obtained.
7.5 Dual Java System Support
An unusual aspect of systems developed by combining Java code compiled using the GNUPro compiler with interpreted Java bytecodes being executed by a third-party Java VM is that there will be two different Java system present at the same time. A significant amount of engineering will have to be performed to enable these two Java systems to co-exist.One of the simplest conflicts that might occur is that both systems might attempt to provide two symbols with the same name. This might occur in the case of the JNI. Both systems might define a JNI routine with the same name. This would occur because both systems are attempting to provide their own version of a routine for their JNI implementation with this name. Reducing the likelihood of this being a major issue, most of the JNI routines are accessed indirectly via function pointers, rather than through well known symbolic names. Should symbol conflicts be a problem, the simplest solution is probably to avoid the conflicts by using macros in C/C++ header files to effectively rename the symbols in such a way as to remove any conflicts. A more complex solution would be to have a single set of generic routines that attempt to ascertain whether they are being invoked by the compiled or interpreted implementation, and then vector execution to the corresponding routine for that implementation.
A second area in which conflicts between the two systems will need to be resolved is in the need for co-existing garbage collection and heap management schemes. For the two systems to co-exist in a meaningful way, it is necessary for them to share, in some way, a single memory pool. A fixed partitioning of available memory into two separate heaps would be highly bad design. The simplest, portable way of achieving this is probably though the JNI. The compiled Java system would have its own memory allocation and garbage collection sub-system, but would use a slab allocator to obtain large new blocks of memory whenever it ran out of memory. When the compiled and interpreted systems were combined, the slab allocator would be configured to use the interpreted VMs JNI interface to interface with an interpreted class that obtained blocks of memory for the slab allocator to use from the interpreted garbage collection system.
The final area of possible conflicts is in access to the underlying low-level hardware, such as any hardware time-of-day clock, or scheduling interrupts. Conflicts in this area should be relatively easy to solve, although the exact details will depend upon the precise nature of the underlying hardware.
Bibliography
The Java Language Specification, James Gosling, Bill Joy, Guy Steele, Addison-Wesley, 1996.The Java Virtual Machine Specification, Tim Lindholm, Frank Yellin, Addison-Wesley, 1996.
The Java Class Libraries, Second Edition, Volume 1 & 2, Patrick Chan, Rosanna Lee, Douglas Kramer, Addison-Wesley, 1998.
Java Virtual Machine Debugger Interface Reference, Sun Microsystems, 1998.
Using GNU CC, Richard Stallman and Cygnus Solutions, Cygnus Solutions, 1997.
Debugging with GDB, Richard Stallman and Cygnus Solutions, Cygnus Solutions, 1997.
Algorithms for Automatic Dynamic Memory Management, R. Jones, R. Lins, Garbage Collection, Wiley, 1996.
Uniprocessor Garbage Collection Techniques, P. Wilson, University of Texas Computer Science department, 1996.
An incremental garbage collector for embedded real-time systems, M. Wallace, C. Runciman, Proceedings of Chalmers Winter Meeting, June 1993.
Real-Time Non-Copying Garbage Collection, P. Wilson, M. Johnstone, ACM OOPSLA Workshop on Memory Management and Garbage Collection, 1993.
List processing in real-time on a serial computer, H. Baker, Communications of the ACM, 21(4):280-94, 1978.